40 lines
1.8 KiB
Markdown
40 lines
1.8 KiB
Markdown
|
|
|
|||
|
|
## 视频地址
|
|||
|
|
https://www.bilibili.com/video/BV1ey4y1q7s4
|
|||
|
|
|
|||
|
|
## ComputerShadder
|
|||
|
|
### 支持原子操作
|
|||
|
|
InterLockedAdd(),Min()/Max(),Exchange()
|
|||
|
|

|
|||
|
|
|
|||
|
|
### 线程同步
|
|||
|
|
GroupMemoryBarrierWithGroupSync()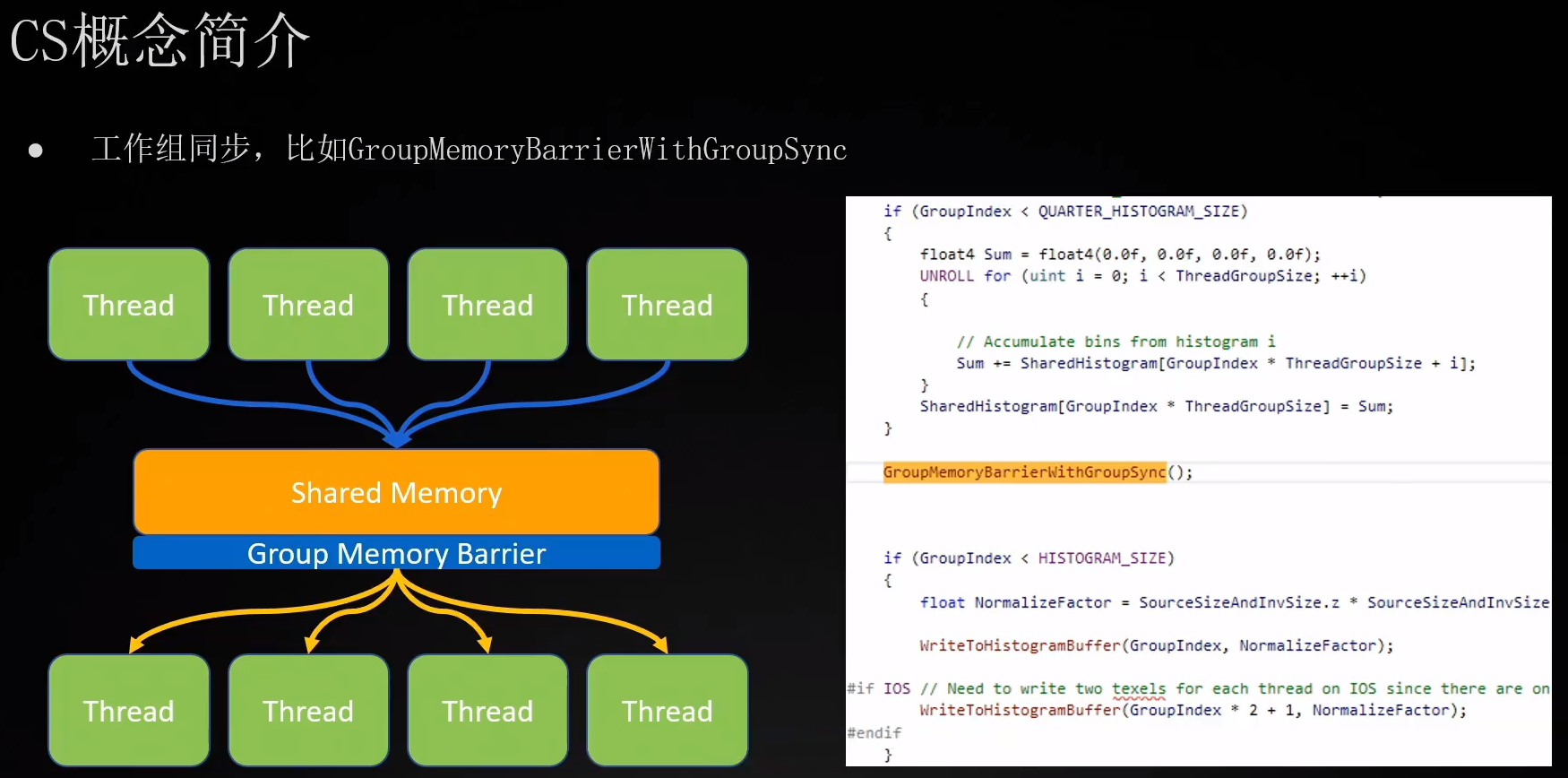
|
|||
|
|
|
|||
|
|
### Shader传入参数
|
|||
|
|
- GroupThreadID(SV_GroupThreadID)
|
|||
|
|
- GroupID(SV_GroupID)
|
|||
|
|
- DispatchThreadID(SV_DispatchThreadID)
|
|||
|
|
- GroupIndex(SV_GroupIndex)
|
|||
|
|
|
|||
|
|
可以在微软的文档中找到具体解释。
|
|||
|
|
|
|||
|
|
### ComputeShader对于PixelShader的优势
|
|||
|
|
PixelShader只能处理当前Shader,ComputeShader是任意位置可写。可以用于编写屏幕空间反射等需要将效果写入任意位置的效果。
|
|||
|
|
可以更好地利用显卡的并线单元。使用二分法循环计算:
|
|||
|
|
|
|||
|
|
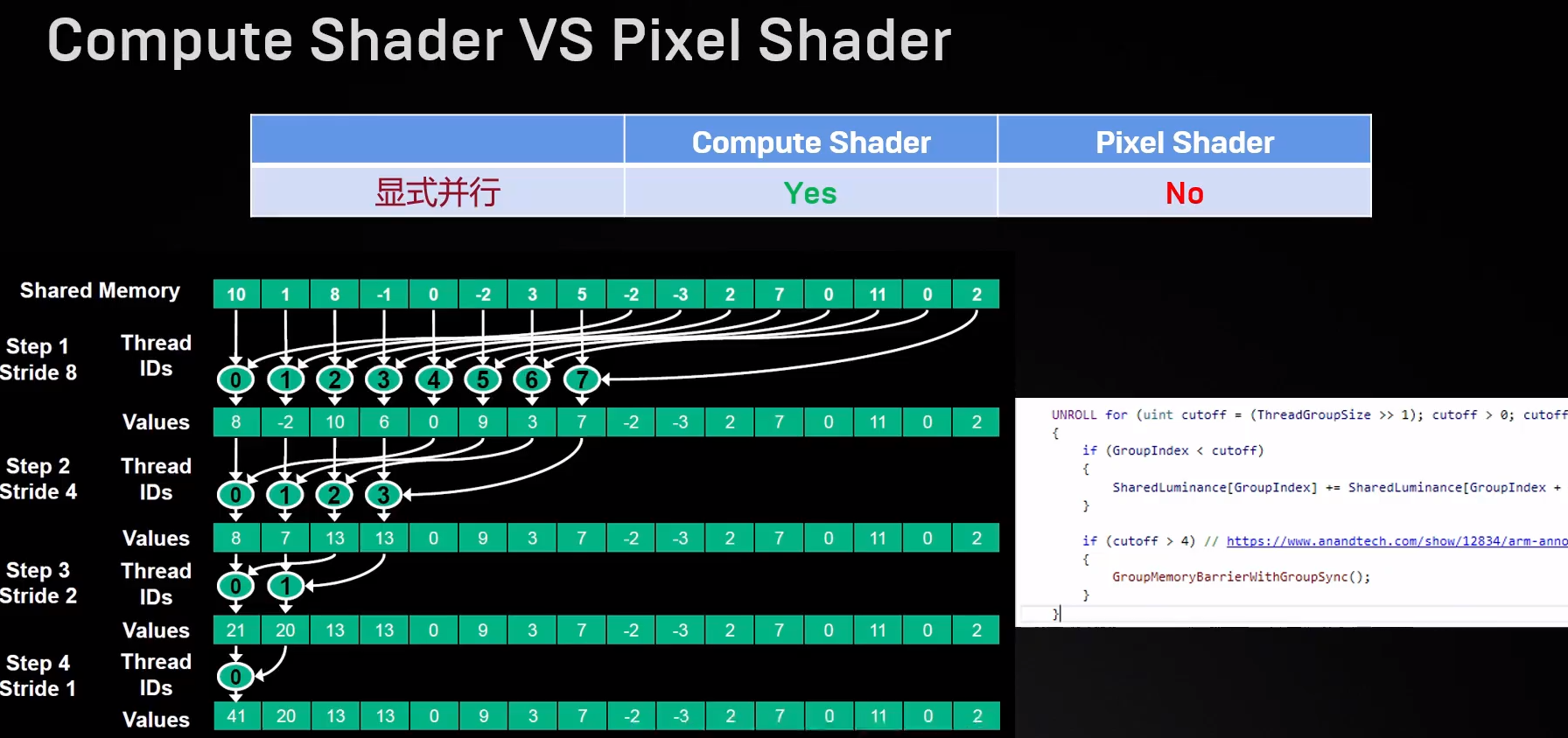
|
|||
|
|
|
|||
|
|
共享内存:举个例子模糊、等需要多次采样各个像素的算法,使用共享内存就可以减少采样次数与消耗。
|
|||
|
|
|
|||
|
|
#### 工作组
|
|||
|
|
工作组会影响共享内存大小,从而影响多次采样像素的效率。但也会影响线程同步,同步速度变慢,也会影响原子操作次数。
|
|||
|
|
|
|||
|
|
### PixelShader对于ComputeShader的优势
|
|||
|
|
- PixelShader可以预加载贴图并且缓存UV,使得读取贴图的效率会非常高。而ComputeShader需要计算出UV,所以做不到这点。
|
|||
|
|
- PixelShader支持FrameBuffer压缩,减少带宽压力。
|
|||
|
|
- PixelShader支持更多的贴图格式。
|
|||
|
|
|
|||
|
|
## ComputeShader优化技巧
|
|||
|
|
- Optimizing Compute Shaders For L2 Locality Using Thread-Group ID Swizzling
|
|||
|
|
- DirectCompute Programming Guild
|
|||
|
|
- DirectCompute Optizations And Best Practices
|