Init
This commit is contained in:
91
03-UnrealEngine/性能优化/UE5 MergeActor使用笔记.md
Normal file
91
03-UnrealEngine/性能优化/UE5 MergeActor使用笔记.md
Normal file
@@ -0,0 +1,91 @@
|
||||
---
|
||||
title: UE5 MergeActor使用笔记
|
||||
date: 2022-09-23 14:28:31
|
||||
excerpt:
|
||||
tags:
|
||||
rating: ⭐
|
||||
---
|
||||
## MergeActor
|
||||
文档地址:文档地址:https://docs.unrealengine.com/5.0/zh-CN/merging-actors-in-unreal-engine/
|
||||
|
||||
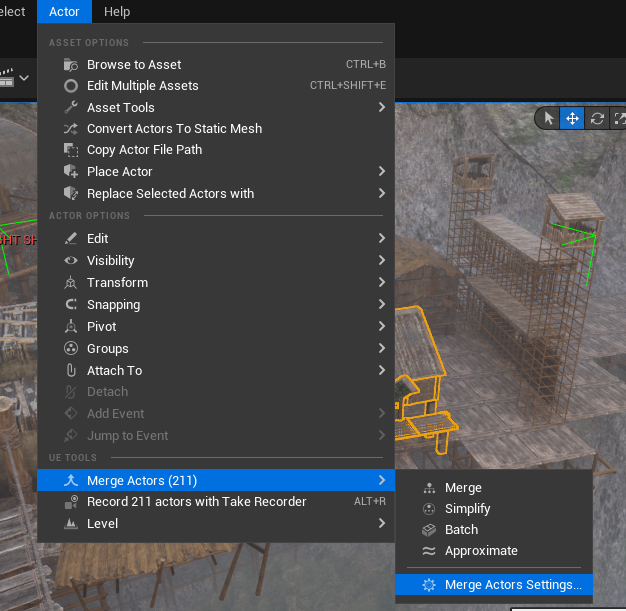
UE5针对Nanite增加了Approximate。使用这些功能建议点MergeActorSettings确认完设置再执行功能。
|
||||
|
||||
|
||||
### Merge
|
||||
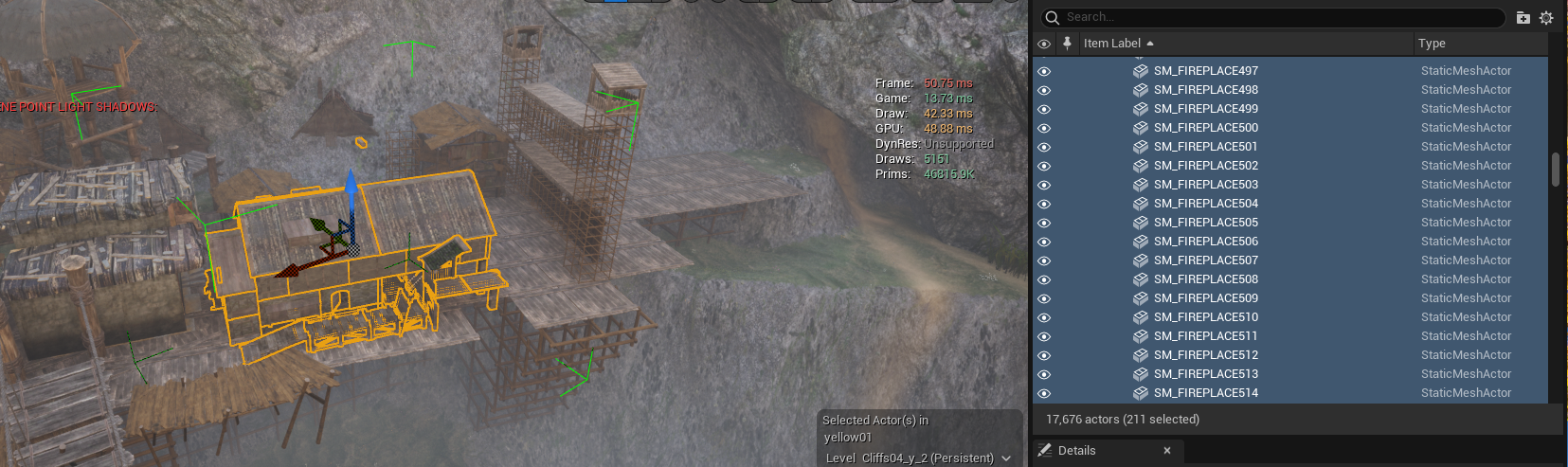
合并模型与材质,DrawCall等于材质数量,不会保留UV。
|
||||
|
||||
比较适合这种由多种小零件组合成的模型:
|
||||
|
||||
|
||||
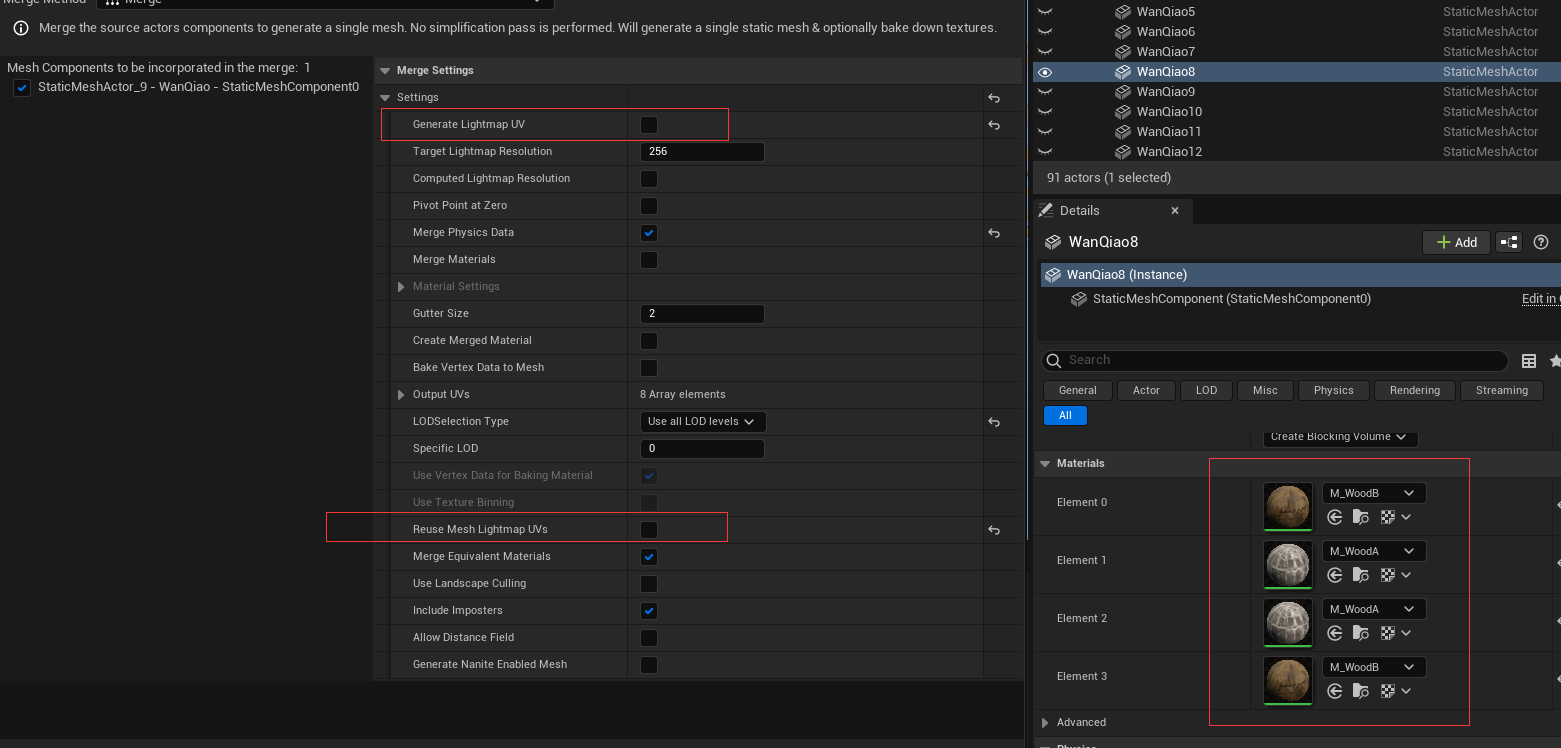
Merge还有一个作用就是可以合并重复的材质、去掉LightMapUV以及生成Nanite。左下角有个Replace Source Actor选项可以代替场景中的Actor。
|
||||
|
||||
|
||||
|
||||
### Batch
|
||||
用于创建instanced Static Mesh components。
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
### Simplify
|
||||
用于生成Proxy Geometry 适合远景物体,**不能用于处理Nanite物体**。 https://docs.unrealengine.com/5.0/zh-CN/proxy-geometry-tool-overview-in-unreal-engine/
|
||||
|
||||
#### HLOD
|
||||
- 把模型分组降低Draw calls
|
||||
- 合并材质和贴图(atlas)
|
||||
- 在远处时自动替换成合并后的Static Meshes
|
||||
- 100% 非破坏性流程,可以随意更改
|
||||
|
||||
### Approximate
|
||||
可以**用于处理Nanite物体**的Simplify版本。
|
||||
|
||||
|
||||
|
||||
#TODO
|
||||
|
||||
https://docs.unrealengine.com/5.0/zh-CN/building-hierarchical-level-of-detail-meshes-in-unreal-engine/
|
||||
|
||||
### 减少Draw calls
|
||||
少量的大物体 替代大量的小物体
|
||||
- 糟糕的剔除
|
||||
- 糟糕的光照贴图
|
||||
- 糟糕的碰撞计算(精度低)
|
||||
- 糟糕的内存占用
|
||||
|
||||
### LODs
|
||||
- 简化模型
|
||||
- 把模型换成另一个更简单的
|
||||
- 远处的模型面数少
|
||||
- 可以把多材质换成单材质
|
||||
|
||||
### 模块化
|
||||
- 模块化可以节省制作时间和内存
|
||||
- 会增加Draw calls
|
||||
- 可以用merge meshes(merge actors)
|
||||
|
||||
### Instanced Rendering
|
||||
- 自动合批:相同网格相同材质 自动合并成一个Draw call
|
||||
- 有时候仍然需要手动设置
|
||||
- 植被和草工具可以帮助做Instancing
|
||||
|
||||
### HLOD
|
||||
- 把模型分组降低Draw calls
|
||||
- 合并材质和贴图(atlas)
|
||||
- 在远处时自动替换成合并后的Static Meshes
|
||||
- 100% 非破坏性流程,可以随意更改
|
||||
|
||||
## 其他
|
||||
### Merge 规则
|
||||
- The more common a mesh AND the lower poly the better (合并常用且面数低的)
|
||||
- Merge only meshes within the same area (只合并同一区域的网格体)
|
||||
- Merge only meshes sharing the same material(合并具有相同材质的mesh)
|
||||
- Meshes with no or simple collision are better for merging(没有或只有基础collision的mesh适合merge)
|
||||
- Smaller meshes or meshes receiving only dynamic are better candidates(小的mesh或者dynamic的mesh适合merge)
|
||||
- Distant geometry is usually great to merge(远处的mesh适合merge , 类似HLOD)
|
||||
|
||||
### Material
|
||||
- 在远距离时,禁用顶点偏移(world position offset),因为在距离很远时,几乎看不到动画效果
|
||||
- 在低性能设备上,可以启用 full rough,慎用 high quality reflection, 启用single-pass linear rendering
|
||||
- Additive can only brighten the material ,while Modulate can only darken the material(**贴花**)
|
||||
- 材质数量要少,使用要尽可能频繁,这样可以减少GPU切换着色器的频率 (减少draw call)
|
||||
486
03-UnrealEngine/性能优化/UE5优化方法与实践笔记.md
Normal file
486
03-UnrealEngine/性能优化/UE5优化方法与实践笔记.md
Normal file
@@ -0,0 +1,486 @@
|
||||
---
|
||||
title: UE5优化方法与实践笔记
|
||||
date: 2022-09-26 10:06:37
|
||||
excerpt:
|
||||
tags:
|
||||
rating: ⭐⭐
|
||||
---
|
||||
|
||||
## 前言
|
||||
- 视频推荐:
|
||||
- https://www.youtube.com/watch?v=ZRaeiVAM4LI
|
||||
- 其他:
|
||||
- https://zhuanlan.zhihu.com/p/629225258
|
||||
- Tomlooman的优化建议:https://www.tomlooman.com/wp-content/uploads/2022/11/Unreal-Engine-Game-Optimization-on-a-Budget.pdf
|
||||
|
||||
GPU Visualizer工具显示命令: **ProfileGPU**
|
||||
CPU优化方法:https://www.unrealengine.com/en-US/blog/how-to-improve-game-thread-cpu-performance
|
||||
### Sample Workflow
|
||||
1. Run `Stat unit`
|
||||
- shows the render thread is taking 50 ms.
|
||||
2. Then run `stat scenerendering`
|
||||
- shows that 25 ms is in the RenderViewFamily
|
||||
- leaving us with 25 ms that the render commands are taking up
|
||||
3. Finally, run `stat sceneupdate`
|
||||
- we see that there is 25 ms in AddLight RT
|
||||
- we see that it is being called 10 times a frame
|
||||
4. We then need to go look at who is calling AddLight via a break point. And see why adding a specific light or lights is so slow. Usually it is the case that a specific light being added in a way that is doing more work than actually needs to be done. (e.g. attaching / reattaching it)
|
||||
|
||||
# 优化前需做
|
||||
- r.vsync 0
|
||||
- t.maxfps 0
|
||||
- SmoothFrameRate=False (Project Settings)
|
||||
- Lighting Built & MapCheck Errors fixed.
|
||||
- Packaged Game build
|
||||
- 使用Standalone进行优化。
|
||||
## 优化笔记
|
||||
r.Lumen.DiffuseIndirect.MeshSDF.RadiusThreshold
|
||||
让物体包围球的半径大于上述两个决定的数值的时候,才参与mesh sdf的软追踪。
|
||||
|
||||
某些情况下,创建移除 WPO/PDO 的材质 LOD 可能不切实际,但这些转换的最终效果在远处很小。用于`r.Shadow.Virtual.Cache.MaxMaterialPositionInvalidationRange`设置一个距离(以厘米为单位),超过该距离将忽略这些材质的缓存失效。
|
||||
为了在这些情况下更好地优化,可以使用启用可选的**单独静态缓存**`r.Shadow.Virtual.Cache.StaticSeparate 1`模式。此模式将物理页面池的大小加倍,以便可以将给定页面中的静态几何与动态几何分开缓存。即使动态几何移动了,也不需要重新绘制静态几何。
|
||||
|
||||
### Nanite
|
||||
r.Nanite.AllowWPODistanceDisable
|
||||
|
||||
### 非纳米变形和树叶
|
||||
|
||||
可以使用骨骼动画变形的几何体,或使用世界位置偏移或像素深度偏移的材质总是使缓存页面每帧无效。根据定义,这些案例也必须是非 Nanite——这更昂贵——因此确保谨慎使用这些功能并控制边界是极其重要的。
|
||||
在某些情况下,例如草地,有时是树叶,仅使用[接触阴影](https://docs.unrealengine.com/5.0/en-US/contact-shadows-in-unreal-engine)就足以替代高分辨率阴影贴图。在前景中需要高细节阴影的情况下,请考虑以下内容以帮助降低性能成本:
|
||||
|
||||
- 非 Nanite 对象仍然遵守常规阴影 CPU 剔除设置,例如`r.Shadow.RadiusThreshold`. 使用这些来帮助控制将这些对象渲染到虚拟阴影贴图中的成本。
|
||||
- 在有很多树叶的场景中,强烈建议使用 禁用粗糙页面中的非 Nanite 对象`r.Shadow.Virtual.NonNanite.IncludeInCoarsePages 0`。或者,考虑在不需要时 [完全禁用粗糙页面。](https://docs.unrealengine.com/5.0/en-US/virtual-shadow-maps-in-unreal-engine#coarsepages)
|
||||
- 在效果不再明显的距离使用网格 LOD 切换到不使用 WPO/PDO 的材料。在某些情况下,可以关闭远处这些对象的动态阴影投射,并完全依赖屏幕空间接触阴影。
|
||||
|
||||
对于平行光,还有其他可用选项:
|
||||
- 距离场阴影接管非 Nanite 几何体,超出由光的级联阴影贴图部分设置的**动态阴影距离可移动光距离。**为远处的非 Nanite 切换到距离场阴影可以显着提高性能,因为该几何体不具有 Nanite 提供的细粒度 LOD 缩放。
|
||||
- 在某些情况下,创建移除 WPO/PDO 的材质 LOD 可能不切实际,但这些转换的最终效果在远处很小。用于`r.Shadow.Virtual.Cache.MaxMaterialPositionInvalidationRange`设置一个距离(以厘米为单位),超过该距离将忽略这些材质的缓存失效。
|
||||
如果运动很明显,这可能会导致阴影“模糊”,并且对象会错误地自我形成阴影,但通常这些伪影是性能和便利性的合理折衷。
|
||||
|
||||
### 普通植被
|
||||
|
||||
普通植被最快,最有效的优化方式是做好LOD,减少culling distance.除此之外,还有两个因素对性能也有一定的影响。
|
||||
- foliage actor的范围
|
||||
foliage actor的默认tile的大小是256,如果一个tile下有大量的植被,而且植被密度非常浓密的时候,这里不仅会引起分区流送引起cluster tree构建的卡顿,也会导致gpu下prepass和basspass消耗过高,因为默认的剔除盒子太大,导致prepass和basspass存在大量的vs的overdraw.
|
||||
- cluster tree遮挡剔除盒子大小
|
||||
cluste tree的剔除盒大小,决定了这一块instance是否绘制,过大的盒子,会引起prepass和basspass的vs阶段的overdraw,过小的盒子,导致存在大量的遮挡剔除查询导致render线程耗时过高,而且也会产生过多的drawcall。引擎对于cluster tree的控制参数都是全局的,有一些component适用,也一些则不合适。过密的component须要提高盒子的粒度,过于稀疏而且面数不高的,可以减少盒子数。因为,如果植被特别影响性能的时候,可以修改引擎支持让这些参数跟着component走。引起cluster tree盒子的因素有点多,这里主要聊三个。
|
||||
|
||||
foliage.MaxOcclusionQueriesPerComponent
|
||||
控制每个component的最多盒子数
|
||||
|
||||
foliage.MinOcclusionQueriesPerComponent
|
||||
控制每个component的最少盒子数
|
||||
|
||||
foliage.MinInstancesPerOcclusionQuery
|
||||
控制每个盒子最小包含的实例数
|
||||
|
||||
如果这个盒子粒度控制好,在植被比较多的情况下,可以在prepass和basspass省下2MS的预算。
|
||||
|
||||
### 贴图优化
|
||||
具体参看:Managing the Texture Streaming Pool:https://www.youtube.com/watch?v=uk3W8Zhahdg
|
||||
大致步骤:
|
||||
- 使用Tools - Audit - Statistics查看贴图占用显存以及场景中的使用数量。
|
||||
- 通过ViewMode - OptimizationViewModes - RequiredTextureResolution 查看贴图在场景中所需要的占用比例是否合适。
|
||||
- 使用批量编辑功能修改Texture资产的MaximumTextureSize到指定Mipmap层级的分辨率即可。
|
||||
|
||||
另一个种方式就是使用SVT。
|
||||
|
||||
## 游戏的优化指标
|
||||
目标性能:30帧 约30ms
|
||||
2000-3000是合理drawcall次数;5000较高;10000有问题
|
||||
|
||||
### 优化建议
|
||||
1. 远景或者不太容易见到的灯光不产生阴影
|
||||
2. Spotlight不要超大开角,可以降低阴影分辨率,衰减半径不要设置过大,只需照亮需要照亮的主题即可,如果不投射阴影可以改成点光源。
|
||||
3. 灯光需要减少级联阴影的使用量,在远景处尽可能得使用距离场阴影
|
||||
1. 方向光:降低DynamicShadowDistanceMoveableLight,Num Dynamic Shadow Cascades的值。适当调整DistanceFieldShadowDistance与DistanceFieldTraceDistance。
|
||||
2. 其他光:降低**Max Draw Distance**,减少渲染范围;控制**Attenuation Radius**、**Cone Angle**减少叠加。具体可以使用**ViewModel - Optimization ViewModes - Light Complexity**来进行检查。
|
||||
3. 其他光:降低ShadowResolutionScale;并且调整亮度,让玩家看不出阴影质量较低。
|
||||
4. 对于**非Nanite物体**的阴影,可以使用**r.Shadow.RadiusThreshold**来减少投射阴影的物体数量。
|
||||
5. VSM
|
||||
1. 局部光:16k,8级Mipmap
|
||||
2. 方向光:16k, 17级Clipmap
|
||||
3. 纹理池上限:`r.Shadow.Virtual.MaxPhysicalPages (4096)`
|
||||
4. Lod精度偏移
|
||||
1. `r.Shadow.Virtual.ResolutionBiasDirectional`
|
||||
2. `r.Shadow.Virtual.ResolutionBiasLocal`
|
||||
5. 减少SMRT的采样次数来提高软阴影的性能。
|
||||
4. Lumen
|
||||
1. 距离场的设置![[Lumen_StaticMeshDistanceFieldSettings.png|1000]]
|
||||
5. Nanite
|
||||
1. UE5.1针对树等植被,采用了直接的建模式树叶而非之前的Mased+卡片的方式实现,此时再配合StaticMesh中NaniteSettings的**Preserve Area**。拉远了树木上的树叶就不会消失了。
|
||||
1. <iframe height=450 width=800 src="https://cdn2.unrealengine.com/p-area-off-opt-0c8757e8275f.mp4" frameborder=0 allowfullscreen> </iframe>
|
||||
2. <iframe height=450 width=800 src="https://cdn2.unrealengine.com/p-area-on-opt-1s-89bb46d92142.mp4" frameborder=0 allowfullscreen> </iframe>
|
||||
2. UE5.1支持了WorldPositionOffset,但这个效果在远距离下并不明显,需要根据距离优化掉。可以通过**View Mode - Optimization View Mode - Evaluate World Position Offset**来查看。
|
||||
6. 控制RayTracing渲染功能的距离与范围
|
||||
1. 按角度与距离剔除
|
||||
1. r.Raytracing.Culling 1
|
||||
2. r.Raytracing.Culling.Radius 10000 (100米)
|
||||
3. r.Raytracing.Culling.Radius 1 (5度)
|
||||
2. 设置光追组
|
||||
1. StaticMeshComponent - RayTracing - Advanced - Raytracing Group Id /Culling Priority
|
||||
7. 针对粒子特效,可以调节Cut Off的裁剪系数,Spawn Time,Spawn Rate等等可以在保证效果的同时来降低粒子数量的参数
|
||||
1. https://www.youtube.com/watch?v=_T-BTiMF7XA
|
||||
2. https://docs.unrealengine.com/4.26/en-US/RenderingAndGraphics/Niagara/EmitterReference/RenderModules/
|
||||
8. 尽可能使用贴花
|
||||
9. 模型优化
|
||||
1. 给模型生成LOD以及HLOD
|
||||
1. Level Of Detail Coloration->Mesh LODs(可以**用红绿蓝三种颜色来**检验不同屏幕尺寸的LOD变化)
|
||||
2. 对于远处会闪烁的模型,需要关闭LOD的`自动计算LOD距离`,并且手动制作LOD。
|
||||
2. 模型转换为Nanite后,可以使用Nanite Tools来检查Nanite转换是否正确
|
||||
3. 如果是**大量OverDraw Nanite模型**,可以使用**UE内置建模工具**的**Merge功能**将模型进行合并。
|
||||
10. 使用剔除功能减少渲染的图元数
|
||||
1. 使用`Stat InitViews`检查当前渲染图元数,以及之后优化完之后的图元数。**View Visibility**、**Occlusion Cull**为剔除消耗,**Processed**、**Frustum Culled**、**Occluded**剔除前后图元变化。
|
||||
2. 给模型的LOD选项中设置**MinDrawDistance、DesiredmaxDrawDistance、CurrentMaxDrawDistance让模型在较远处被剔除**,适合一些细小的装饰类模型。
|
||||
3. 使用剔除用Volumn。
|
||||
11. 材质、蓝图等等,如果可以创建实例就使用实例
|
||||
12. 综合优化视频
|
||||
1. Adjusting Your Content to Perform on Target Hardware https://www.youtube.com/watch?v=Ln8PCZfO18Y
|
||||
13. 贴图优化
|
||||
1. 调整贴图的LOD Bias
|
||||
2. 使用rdTexTools 插件优化贴图
|
||||
14. 使用MergeActor工具,将模型转化成Instance或者将细碎的模型组合成一个模型。
|
||||
15. 调整材质:减少材质复杂度以及使用的材质指令量。EPIC给出的建议:300左右正常、**500+优化**、**1000+尽量减少**。
|
||||
16. HLOD 估计适合组合拼装的房子 https://www.youtube.com/watch?v=WhcxGbKWdbI
|
||||
1. 知乎介绍文章:https://zhuanlan.zhihu.com/p/77509062
|
||||
2. HLOD需要在世界设置中的LODSystem中打开。
|
||||
17. 场景模型剔除 推荐视频:https://www.youtube.com/watch?v=6WtE3CoFMXU
|
||||
1. Show-Visualize-Advanced-CameraFrustums,可以查看摄像机范围外的物体与遮挡物体。
|
||||
2. Volumn
|
||||
1. CullDistanceVolumn: 根据对象距摄像机的距离及其尺寸,对对象进行剔除(即不绘制到屏幕上)。当对象小到可被视为不重要时,即可不绘制对象,从而优化场景。尺寸是按照边界框的最长边计算的,而剔除距离是根据与该尺寸最接近的距离计算的。
|
||||
2. HierarchicalLODVolumn
|
||||
3. MeshMergeCullingVolumn:与HLOD有关
|
||||
4. PrecomputedVisibilityVolumn:这类体积会保存Actor的可视性,以了解它们在场景中的位置。应仅将这些体积放置在玩家可以到达的区域。(视频是把玩家可以到的地方直接放满了)
|
||||
3. Debug方法
|
||||
1. FreezeRendering:Foliage.Freeze、FX.FreezeGPUSimulation、FX.FreezeParticleSimulation
|
||||
2. r.VisualizeOccludedPrimitives1
|
||||
3. ToggleDebugCamera
|
||||
18. UE5 OpenWorld WorldComposition Datalayer ,里面有附带大世界的HLOD 以及Nanite生成方法以及对应的CommanLet:https://www.youtube.com/watch?v=ZxJ5DG8Ytog
|
||||
|
||||
# 场景
|
||||
在蓝图中放置多个&多层StaticMeshComponent结构,在移动时会爆卡。可以在子Component中勾选***Use Attach Parent Bound***即可避免多层级的BoundingBox更新而导致卡顿。
|
||||
|
||||
|
||||
![[UE5 MergeActor使用笔记]]
|
||||
|
||||
### DLSS与动态分辨率
|
||||
DLSS 在5.03上没有效果,动态分辨率不支持PC。
|
||||
|
||||
https://docs.unrealengine.com/5.0/en-US/dynamic-resolution-in-unreal-engine/
|
||||
### 蓝图的方法
|
||||

|
||||
|
||||
### c++的方法
|
||||
```
|
||||
GEngine->GetDynamicResolutionStatus()->SetEnabled(true);
|
||||
```
|
||||
将 _SetEnabled_ 设置为 **false** 可将其禁用。
|
||||
|
||||
>在实际启用或禁用动态分辨率时,游戏线程逻辑掌握最终程序控制权限,所以如果你是用蓝图在运行时启动它,这会优先于代码设置。要将游戏用户设置恢复到初始状态,请使用以下命令行:
|
||||
```
|
||||
GEngine->GameUserSettings->ApplyNonResolutionSettings();
|
||||
```
|
||||
|
||||
### 命令行
|
||||
你可以使用 **运算模式(Operation Mode)** 设置如何在游戏中覆盖和使用动态分辨率,设置在游戏中覆盖它和使用它的方式。为了控制这种模式,在项目所对应平台(Xbox One、PlayStation 4等)的平台配置描述(或设备描述)中,你可以使用下列控制台命令:
|
||||
```
|
||||
r.DynamicRes.OperationMode
|
||||
```
|
||||
|
||||
使用下列数值之一来设置运算模式如何针对项目的平台工作:
|
||||
- **1** 是根据游戏用户设置状态(在C++或蓝图中设置)启用动态分辨率。
|
||||
- **2** 是无论游戏用户设置状态如何都启用动态分辨率。
|
||||
|
||||
启用动态分辨率后,下列控制台变量会设置屏幕百分比的最大值和最小值,以及在降低分辨率之前任何给定帧的最大预算。如果你不设置,这些变量都有默认值:
|
||||
|
||||
| 控制台变量 | 默认值 | 描述 |
|
||||
| -------------------------------- | ------ | ------------------------------------------ |
|
||||
| r.DynamicRes.MinScreenPercentage | 50 | 设置要使用的最小屏幕百分比。 |
|
||||
| r.DynamicRes.MaxScreenPercentage | 100 | 设置用于分配渲染目标的最大主要屏幕百分比。 |
|
||||
| r.DynamicRes.FrameTimeBudget | 33.3 | 设置帧预算(以毫秒为单位)。 |
|
||||
|
||||
|
||||
你可以使用Unreal Engine中的"设备描述(Device Profiles)"窗口设置和管理配置文件。可以通过"文件(File)"菜单选择 **编辑(Edit)> Developer Tools(开发者工具)> Device Profiles(设备描述)** 来访问此窗口。
|
||||
|
||||
### 暂停和恢复动态分辨率
|
||||
有时你可能需要为项目启用动态分辨率,但你又不想对主大厅之类的区域启用。动态分辨率可以随运作模式暂停和恢复。下列控制台变量可用于设置动态分辨率的运算模式:
|
||||
```
|
||||
r.DynamicRes.OperationMode
|
||||
```
|
||||
| 数值 | 描述 |
|
||||
| ---- | ------------------------------------------ |
|
||||
| 0 | 禁用(默认) |
|
||||
| 1 | 根据GameUserSettings中使用的设置启用。 |
|
||||
| 2 | 无论GameUserSettings中的设置如何都会启用。 |
|
||||
|
||||
## DLSS 与 FSR
|
||||
UE5使用DLSS时需要关闭TAA,并且调整[[ScreenPercentage与描边宽度问题解决]]
|
||||
|
||||
### DLSS
|
||||
- 下载地址:https://developer.nvidia.com/rtx/dlss/get-started#ue-version
|
||||
|
||||
### FSR
|
||||
- 使用方法与参数详解:https://zhuanlan.zhihu.com/p/437537928
|
||||
- 下载地址:https://gpuopen.com/learn/ue-fsr2/
|
||||
|
||||
# 内存数据查看
|
||||
- stat llm:查看**虚拟内存数据**。需要在启动方式里添加`-llm`才会有数据。
|
||||
- MemoryInsight:需要在启动方式里添加`-trace=memory`,之后才能在UnrealInsight中查看。
|
||||
|
||||
# 材质优化 MIN/MAX DRAW DISTANCE
|
||||
使用DistanceCullFade节点将过远的部分给Cull掉。
|
||||
![[Unreal-Engine-Game-Optimization-on-a-Budget_MINMAX DRAW DISTANCE.png]]
|
||||
|
||||
# FREEZERENDERING
|
||||
冻结渲染以此查看剔除情况。
|
||||
- ‘FreezeRendering’ + ; (semi-colon) to fly with DebugCamera
|
||||
- Verify occlusion is working as expected
|
||||
- ‘pause’ (Freeze Game Thread)
|
||||
|
||||
# LIGHT CULLING (Stationary & Movable)
|
||||
- Automatic ScreenSize culling not strict enough
|
||||
- MinScreenRadiusForLights (0.03)
|
||||
- Cull earlier case-by-case
|
||||
- MaxDrawDistance
|
||||
- MaxDistanceFadeRange
|
||||
- Profiling
|
||||
- Show > LightComplexity (Alt+7)
|
||||
- Show > StationaryLightOverlap
|
||||
- ToggleLight
|
||||
|
||||
# LEVEL STREAMING
|
||||
关卡流调试方法
|
||||
- Streaming Volumes vs. Manual Load/Unload
|
||||
- Camera Location based (caution: third person view and cinematic shots)
|
||||
- Cannot combine both on a specific sublevel, can mix within the game
|
||||
- Profiling
|
||||
- stat levels
|
||||
- Loadtimes.dumpreport (+ loadtimes.reset)
|
||||
- Unreal Insight
|
||||
- UnrealInsight相关标签:Look for level load & “GC” bookmarks
|
||||
- UnrealInsight相关追踪内容:loadtime,file categories
|
||||
|
||||
# Animation
|
||||
## ANIMATION: FAST PATH
|
||||
- Allow ‘Fast Path’ by moving Computations out of AnimGraph (into EventGraph)
|
||||
- Use WarnAboutBlueprintUsage to get warnings in AnimGraph
|
||||
- Profiling
|
||||
- stat anim
|
||||
|
||||
## ANIMATION: QUICK WINS
|
||||
- **Update Rate Optimization (URO) for distant SkelMeshes**:根据距离调整骨骼物体的更新频率,该选项位于SkeletalMeshComponent。
|
||||
- VisibilityBasedAnimTickOption (DefaultEngine.ini)
|
||||
- OnlyTickPoseWhenRendered
|
||||
- AlwaysTickPoseAndRefreshBones
|
||||
- …
|
||||
- More Bools!
|
||||
- bRenderAsStatic :UE5.2不存在该选项。
|
||||
- bPauseAnims:该选项位于SkeletalMeshComponent。
|
||||
- bNoSkeletonUpdate:该选项位于SkeletalMeshComponent。
|
||||
|
||||
# DrawCall优化相关
|
||||
使用**Stat DrawCount** 可以参看当前视角所有Pass所有DrawCall。
|
||||
|
||||
使用**Stat SceneRendering** 可以查看Mesh Draw Call。
|
||||
|
||||
# Shadow优化
|
||||
原文:https://zhuanlan.zhihu.com/p/644620609
|
||||
## 阴影
|
||||
阴影主要聊一下平行光的两个解决方案,一个传统的[CSM](https://zhida.zhihu.com/search?content_id=231379699&content_type=Article&match_order=1&q=CSM&zhida_source=entity),一个是ue5配合nanite的[VSM](https://zhida.zhihu.com/search?content_id=231379699&content_type=Article&match_order=1&q=VSM&zhida_source=entity).传统的CSM效果最好,没有噪点,也没有BUG,但是走了Nanite的话,CSM跟nanite配合是水士不服。UE5主推的VSM,性能最好,但是bug多,有噪点,但是又没办法跟距离场配合,开启了VSM,平行光的阴影只有VSM这一种,真是又爱又恨。
|
||||
|
||||
### csm
|
||||
CSM的实行网上教程很多,这里主要聊优化手段。
|
||||
- CSM缓存
|
||||
可以通过r.Shadow.CSMCaching修改为1,开启csm缓存.它会为静态和动态的对像分别启用一张深度图,动态的深度图每帧都会重绘,但是可以通过r.Shadow.CacheWPOPrimitives调整,让WPO的也强制缓存。当两帧平行光没有变化,而且两帧的CSM重叠超过一个阈值的时候,CSM会复用上一帧的深度图,这个阈值通过r.Shadow.CSMScrollingOverlapAreaThrottle调整,默认是0.75。这个CSM缓存在低分辨率下的时候也个好优化,对于高分辨率,深度图失效的时候会重现申请,申请这个RT是个不少的消耗,这一点要注意。
|
||||
|
||||
- CSM层遮挡剔除
|
||||
CSM有好多层,如果前面有个建筑物很高,完全档住人你的视线,这里CSM,远处的层级照样绘制深度,这个是没有必要的,可以通过遮挡剔除优化掉,UE也做了这个优化。过能r.Shadow.OcclusionCullCascadedShadowMaps修改,让不在视野范围的深度图不参与计算,这个是个不错的优化,最好开启。
|
||||
|
||||
- 调整屏幕占比factor
|
||||
对于一些特别远的,屏幕占比很低的物体,没必要去生成深度,可以通过修改r.Shadow.RadiusThreshold生成深度图的对像的半径阈值。
|
||||
|
||||
- 强制使用LOD
|
||||
可以通过r.ForceLODShadow调用生成阴影深度的LOD,这个是个大优化。
|
||||
|
||||
- 调整分辨率
|
||||
这个优化是最好的,直接把分辨率降低,消耗直接变低。r.Shadow.MaxCSMResolution可以通过此参数调整csm每层的分辨率。
|
||||
|
||||
- 逐帧更新
|
||||
因为csm有很多层,对于远处的层,没必要每帧都更新,可以在csm缓存的代码里,修改一下,就可以做到远处的层级逐帧更新,这个优化,可以把CSM的性能提高了好多。
|
||||
|
||||
- 代理阴影
|
||||
对于非nanite的网格体,有强制使用LOD,可以降低深度图对像的面数,但是对于nanite,前面的手段是不生效的。对于nanite来说,走的是自已的[raster](https://zhida.zhihu.com/search?content_id=231379699&content_type=Article&match_order=1&q=raster&zhida_source=entity)。但是很多时候nanite光栅化出来的面数非常巨大,引起nanite切换lod失效的因素非常多。所以对于那些远处,又或者自投影细节比较少的网格体,可以使用代理nanite阴影去解决。修改引擎支持proxyshadow component,只设置影响深度pass,其它pass都不绘制,可以解决nanite在csm情况下LOD失效的时候减面优化性能。
|
||||
|
||||
上面的手段,基本都是对于非nanite的有效,对于nanite的,上面的优化手段基本都是失效的,nanite的网格全是gpu driver的,有自已的渲染管线。
|
||||
|
||||
### vsm
|
||||
VSM的原理就是一张大VT,不同clipmap范围的VT页分辨率不一样,同时动静分离,在平行光不变的情况下,静态页面复用,只重绘动态的页面,同时对于动态的页面缓存,非nanite的网格体也可以缓存,可以通过r.Shadow.Virtual.Cache.MaxMaterialPositionInvalidationRange调整数值,让离自已一定范围内的非nanite才失效,超过强行缓存。对于平行光不停在变情况的情况下,所有页面都在失效,这时可以关闭缓存(r.shadow.vsm.cache),反而可以提高一点性能,节省一些显存,因为不分动静页,也不会分析哪些而页面失效。
|
||||
|
||||
目前VSM的问题比较多,主要集中在两个方面,bug多和噪点问题,bug比如,页面分析出错,应该失效的页面不失效,大范围WPO导致超出cluster bound box,导致深度图被clamp在一个范围内,同一个物体的深度在不同clipmap下的页面不一至 ,导致一些奇奇怪怪的阴影错乱问题, 噪点问题是算法决定了,smrt,判断是否是软阴影的一个算法,当一个像素发送射线过多,会导致性能不行,过低,噪点严重。总体来说,VSM,还不能完全线上使用。
|
||||
|
||||
VSM配合nanite使用,性能是非常好的,下面讲一下VSM的一些优化手段,主要是降分辨率。
|
||||
|
||||
- clipmap范围与页面密度
|
||||
可以通过调用r.Shadow.Virtual.Clipmap.FistLevel和LastLevel来调clipmap的覆盖范围,在不同的clipmap有同的页面覆盖面积。这里不仅可以优化性能,也可以优化显存。
|
||||
|
||||
- 分辨率bias
|
||||
在clipmap范围不变的情况下,可以通过调整每个页面的覆盖范围,通过调整r.Shadow.Virtual.ResolutionLodBiasDirectional来修改平行光的页面覆盖面积以达到降分辨率的处理
|
||||
|
||||
- 非nanite物体wpo强制缓存
|
||||
调整r.Shadow.Virtual.Cache.MaxMaterialPositionInvalidationRange数值,让在数值范围内的WPO强制使用缓存。
|
||||
|
||||
### 距离场阴影
|
||||
距离场阴影的原理是,把屏幕切tile,在cs里,找到每个tile对应有可能overlap的距离场,然后每个tile每个像素追踪距离场,就可以知道像素是否在阴影下。距离场阴影性能非常好。对于远处的物体阴影 ,都建议开距离场阴影。但是,在VSM开启的情况下,Nanite物体距离场是失效的。
|
||||
|
||||
对于点光的阴影,可以通过在远距离时使用距离场阴影,近距离影时使用shadowmap。
|
||||
|
||||
这里提示一点,在室内或者完全不受平行光的环境下,可以把平行光的阴影关掉,用距离场去代替。
|
||||
|
||||
### 接触阴影
|
||||
接触阴影主要是屏幕空间下的通过hzb追踪得来的阴影,他会有效果表现下比较差,但是对于植被这种,特别适合,当场景大量存在存被的情况下,可以开启接触阴影。
|
||||
|
||||
### 点光源
|
||||
对于点光在GPU端,分两种情况,直接阴影和间接阴影。有三种阴影选择,深度图,接触阴影,距离场,接触阴影效果不好,深度图精度最高,支持动态物体,但是很影响性能,距离场性能最好,但是不支持动态物体。对于远一点的,可以用距离场代替,随着距离变近,切换到shadowmap,把光源交由逻辑层管理。
|
||||
|
||||
如果一个光源间接光照强度大于0,此光源就会在[lumen scene](https://zhida.zhihu.com/search?content_id=231379699&content_type=Article&match_order=1&q=lumen+scene&zhida_source=entity)生效,在lumen scene里不仅要计算光照,也要计算阴影,包括离屏阴影,性能消耗不低,无论使用shadowmap还是距离场,这里交由脚本层管理,过远的把间接光照强度调成0,不参与lumen scene.
|
||||
|
||||
## [RVT](https://zhida.zhihu.com/search?content_id=231379699&content_type=Article&match_order=1&q=RVT&zhida_source=entity)
|
||||
RVT的使用教程知乎非常多,这里聊一下性能优化点。对于贴图混合层特别多的时候,用RVT可以优化非常大的性能,特别是地形,但是RVT有时候也会突然消耗非常高,可达3MS以上,下面各个聊。
|
||||
|
||||
### produce与upload
|
||||
当VT不存在,或者MIP级别不匹配的时候,引擎会从磁盘(svt)或者通过drawcall(rvt)生成对应的tile,这个过程叫produce,当生成后,就会upload到gpu中,更新indirect table和vt图集,这个过种叫upload.
|
||||
|
||||
### produce
|
||||
svt的produce不影响性能,主要影响性的是地形的rvt的produce,因为地形的图层太多了,这里会通过调用地形的材质drawcall生成对应的vt tile.这里性能消耗是不低的,可以通过r.VT.MaxTilesProducedPerFrame调整数量,注意,这个参数是包括svt的tile数量。
|
||||
|
||||
### upload
|
||||
一般upload不会产生GPU的消耗,除非你的upload数量非常高。可以通过r.VT.MaxUploadsPerFrame调整每帧的upload数量,编辑下通过r.VT.MaxUploadsPerFrameInEditor调整。
|
||||
|
||||
### VT池问题
|
||||
当VT池不足的时候,vt池会不停的切换mip以降显存,这里GPU的VT消耗就会起来。可以通过命令r.VT.Residency.Show查看哪些VT池不足,也可以通过r.VT.Residency.Notify,当对应的池不足切mip的时候,屏幕下会有打印warning,找到对应的池,在配置文件里增大显存。
|
||||
|
||||
### 地形
|
||||
地形用RVT去减少采样是个非常大的优化,另外RVT支持离线烘倍,可以把低的mip离线烘倍,减少切mip的时候的draw call发生以优化性能。通过RVT Volumn下的虚拟纹理构建,把低的MIP烘倍出来。
|
||||
|
||||
## Nanite
|
||||
nanite是UE5最稳定,性能最好的新技术,对于实现原理,没有想像中这么复杂,可以去看一下知乎大佬丛越系列的文章,讲的非常详细,这里聊一下nanite遇到的性能问题。
|
||||
|
||||
### WPO
|
||||
WPO非常影响性能,当cluster剔除后,光栅化后出来的面数也不低,全开WPO,会让vibility buffer生成性能翻倍,这里可以使用世界位置偏移禁用距离调整,超过距离后WPO禁用
|
||||
|
||||
### Mask
|
||||
当有mask材质的时候,没办法通过HZB做剔除,只能先光栅化出来才能通过alphatest来决定去流,overdraw非常严重,对于nanite的材质,最好禁用mask材质。使用mask材质性能非常低,之前有测试过,有mask性能直接减半。
|
||||
|
||||
### LOD减面失效问题
|
||||
nanite的减面是要依赖平滑法线组去决定三角面是否能合并,如果一个模形导出的时候没有平滑法线组,UE会有warning,这个要特别注意,如果没有平滑法线组,面数非常爆裂。
|
||||
|
||||
### Drawcall问题
|
||||
nanite的bass pass是通过在屏幕空间切tile,每个tile有要用到drawcall的材质,CPU端是不知道此时GPU端哪些材质是否draw,所以nanite的draw call是在CPU端,把加载进来的所有材质都发起drawcall,每个drawcall是一个quad,没有在屏幕的时候在vs阶段就culling掉.正常来说,一个culling掉的drawcall是基本不耗时的,但是在一些老显卡(20系),一个culling掉的drawcall,也会有小耗时,如果材质多的话,这些culling掉的drawcall是个不小的消耗。
|
||||
|
||||
### 破面问题
|
||||
引起破面的问题主要有下面几个因素,但是几个因素引起的表现不太一样,下面一个一个聊。
|
||||
|
||||
### 实例数
|
||||
nanite在raster的时候会限制BVH node节点数量,可以通过r.Nanite.MaxNodes去调整,当实例数超过上限的时候,场景每帧会随机掉面。
|
||||
|
||||
### cluster数
|
||||
这里有两个类型cluster,一个是candicate cluster,一个是visiable cluster,分别通过r.Nanite.MaxCandidateClusters和r.Nanite.MaxVisibleClusters,当场景cluster数量足的时候,场景会随机掉失cluster,整个画面在闪烁。
|
||||
|
||||
对于实例数和cluster数的统计,可以通过nanitestats去看到当前的数据,可能数据非常接近上限的时候,就要调整,这里要注意一点,当使用VSM的时候,如果在VSM的view这些数量也超过了,会导致深度生成每帧都不一样,阴影会错乱.
|
||||
|
||||
### nanite流送池显存不足
|
||||
nanite是通过每帧的feedback去让CPU发起流送的,当流送池显存不够的时候,就是流送低的cluster tree,这个时候整个场景的面数非常低,而且会破面。
|
||||
|
||||
### cluster id上限
|
||||
这个没找到原因,当上述所有条件都足够的情况下,仍然会出现随机破面,画面闪烁的问题。当场景存在大量的nanite,而且每个nanite实例都是分离的,最后退化一个cluster的时候,这个cluster仍然很多,这个时候,也会随机破面,目前怀疑是跟 cluster id上限的问题。主要出现在植被非常多的时候。
|
||||
|
||||
## Lumen
|
||||
UE5默认lumen是把效果,质量都是拉满的,如果默认使用lumen的参数,性能很炸。对于lumen,反而bug比较少,主要问题是在集中在性能问题。lumen对场景的效果的提升确实有的,但是很多时候,质量拉满和质量很低的情况下,画面其实看不出有多少区别,所以,在我看来,lumen要用,但不须要很高的质量,基本于这个观点出现,lumen就有很多地方可以优化,如果当某个地方须要很高lumen质量的时候,可以在拉一个新的post process volume,提高lumen的质量。lumen整体分成三个部分,lighting,probe gather,反射,下面集中围绕这三个聊一下优能优化的点。另外,想了解lumen的实现,可以参考丛越大佬的文章,写得非常详细。
|
||||
|
||||
### Lighting速度
|
||||
lumen首先通地在lumen的direct ligting,再加上radiosity的得到每一个patch的lighting,最终combine lighting成indirect lighting.在接下的阶段final gather中,放入probe去trace,得到final lighting.这里有两个参数比较影响性能。
|
||||
|
||||
- direct lighting速度
|
||||
可以通过修改r.LumenScene.DirectLighting.UpdateFactor参数和LumenSceneLightingUpdateSpeed两个参数控制更新速度,前者是分母,后者是分子,这两个参数共同决定了当前帧分配更新图集大小。此图集通过PriorityHistogram中收集优先级的surface cache的tile放入到更新图集,从而达到分帧更新。
|
||||
|
||||
- final gather速度
|
||||
总体流程跟上面类似,通过r.Lumen.ScreenProbeGather.RadianceCache.NumProbesToTraceBudget和LumenFinalGatherLightingUpdateSpeed参数总同决定了final gather阶段最大的trace probe数量,在SelectMaxPriorityBucketCS中选择优化级大的,而且小于上述两个参数共同决定的最大上限probe数去trace.
|
||||
|
||||
### 追踪距离
|
||||
可以通过r.Lumen.TraceDistanceScale和LumenMaxTraceDistance去决定在lumen下距离场的最大追踪距离。这两个参数是影响整个lumen须要距离场cone trace追踪的所有pass,包括final gather的radian cache trace,radiosity的trace,reflect的trace,减少追踪距离,可以优化性能,但是会带来一些不想要的后果,比如反射不到,lumen scene阴影漏光(导致场景有些地方会有从亮到暗的过程),泄露天光等。这里可以在不同区域拉不同的pp盒子,在一些野外,把追踪距离设置小一点提高性能,在一些封闭的地方或者须要反射的地方,可以把追踪距离设置大点。
|
||||
|
||||
### 离屏阴影
|
||||
lumen scene的lighting不仅要算colour,也要计算阴影,它不仅是当前屏幕的,是包括整个surface cache的,对于离屏阴影,UE默认使用mesh object sdf去追踪,如果场景存在大量物体,每个物体都有[mesh sdf](https://zhida.zhihu.com/search?content_id=231379699&content_type=Article&match_order=1&q=mesh+sdf&zhida_source=entity),这样子每个surface cache tile对应的可能对交的mesh sdf非常多,每个一像素对各个mesh sdf追踪是个很大的性能问题,而且对于离屏的阴影,大部分是不须要mesh sdf去追踪,野外大场景,如果一个mesh太小,就算lumen scene 露光也看不出来,对于室内,存在小的sdf漏光找美术去调整就好。
|
||||
|
||||
能过r.LumenScene.DirectLighting.OffscreenShadowing.TraceMeshSDFs设置为0,关闭离屏的mesh sdf trace,使用global sdf去trace.
|
||||
|
||||
### Mesh SDF
|
||||
mesh sdf是lumen的核心,就我看来,目前lumen的消耗有80%来源于mesh sdf,用到mesh sdf的地方非常多。可以通过LumenSceneDetail和r.Lumen.DiffuseIndirect.MeshSDF.RadiusThreshold共同控制,让物体包围球的半径大于上述两个决定的数值的时候,才参与mesh sdf的软追踪。这个优化非常大,特别场景存在大量的小物体的时候,比如植被,这些小物体对于lumen scene的贡献非常低,当然,除了反射。为了解决反射这种情况,我们并没有使用上面的参数控制小物体距离场生效与否,我们直接把小物体的距离场全都默认关闭,这样子,对于须要反射的地方,小物体手动开启距离场。
|
||||
|
||||
另外,调整LumenSceneDetail不仅会影响mesh sdf的culling,也会导致mesh card的丢失,这个参数会引够mesh card小于某个分辨率的时候也会culling掉,在surceface cache视图可以看到很多黄色图块(黄色的代表culling掉,紫色代表没有surface cache),这会引起光照的异常(黑影)。
|
||||
|
||||
### TraceProbe数量
|
||||
在final gather阶段是非常耗时的,最直观的影响因素就是trace射线的数量,它是由八面体probe的密度,每个probe trace的射线数量共同决定。probe的密度通过r.Lumen.ScreenProbeGather.DownsampleFactor和LumenFinalGatherQuality共同决定,八面体,每个面的trace线射数量由r.Lumen.ScreenProbeGather.TracingOctahedronResolution和LumenFinalGatherQuality共同决定。这个参数数值,可以在不同的情况调整不同的数值,在野外调到最低,在室内或者封闭的地方相应调高。
|
||||
|
||||
### 反射分辨率
|
||||
这个非常影响性能,这个目前没找到优化方案,最快的解决方式是降低反射buffer的分辨率,须要高精度的反射,比如达到镜面反射的情况,把pp盒的lumen反射质量调高,其它情况默认调到中档质量,低质量是没有反射。
|
||||
|
||||
lumen默认管方都是质量拉满的,可以调优的地方非常多,另外,lumen非常吃显存,对于显存部分的,有机会在显存篇幅里介绍。
|
||||
|
||||
### 异步Lumen
|
||||
lumen在5.1后支持了异步lumen,这个是依赖GPU Async Compute,这个开启后在我们项目Lumen能节省1~2ms的消耗。
|
||||
|
||||
- 异步Light Probe Gather
|
||||
首先要支持GSupportsEfficientAsyncCompute,AMD默认支持,N卡默认关闭,可以通过命名行ForceAsyncCompute强制打开。
|
||||
|
||||
|
||||
|
||||
另外,通过r.LumenScene.DirectLighting.ReuseShadowMaps关闭lumen scene下的复用阴影的shadow map,使用距离场阴影代替,注意,这会导致动态骨骼在lumen scene没有阴影,而且距离场阴影是很难跟shadowmap的阴影一致的,这会导致两种方式下final lighting会不一样。r.Lumen.DiffuseIndirect.AsyncCompute打开支持异步light probe gather,通过以上三个,异步Light Probe Gather就支持了。
|
||||
|
||||
- 异步Reflect
|
||||
在r.LumenScene.DirectLighting.ReuseShadowMaps关闭下,异步反射可以通过r.Lumen.Reflections.AsyncCompute打开了。
|
||||
|
||||
- 异步Lighting
|
||||
可以通过r.LumenScene.Lighting.AsyncCompute打开异步lighting.
|
||||
|
||||
通过上面三个把异步lumen全部打开的情况下,在已经经过极致优化的lumen下,还可以优化到1到2MS,把lumen在GPU的耗时压得很低,而且不失效果。
|
||||
|
||||
## 植被问题
|
||||
植被有两个方向可以走,nanite与普通植被,各有利弊。
|
||||
|
||||
### nanite植被
|
||||
当植被开启nanite后,性能可以提高一倍以上,就算面数非常高,不可视的面都在nanite culling介段剔除掉。nanite植被有两个问题非常影响性能,wpo和mask,wpo前面nanite有提到,可以超过一定的距离禁用。对于mask材质,建议走实体模型。另外,当植被数量到达一定程度,nanite cluster会随机丢失造成画面闪烁。
|
||||
|
||||
### 普通植被
|
||||
普通植被最快,最有效的优化方式是做好LOD,减少culling distance.除此之外,还有两个因素对性能也有一定的影响。
|
||||
|
||||
- foliage actor的范围
|
||||
foliage actor的默认tile的大小是256,如果一个tile下有大量的植被,而且植被密度非常浓密的时候,这里不仅会引起分区流送引起cluster tree构建的卡顿,也会导致gpu下prepass和basspass消耗过高,因为默认的剔除盒子太大,导致prepass和basspass存在大量的vs的overdraw.
|
||||
|
||||
- cluster tree遮挡剔除盒子大小
|
||||
cluste tree的剔除盒大小,决定了这一块instance是否绘制,过大的盒子,会引起prepass和basspass的vs阶段的overdraw,过小的盒子,导致存在大量的遮挡剔除查询导致render线程耗时过高,而且也会产生过多的drawcall。引擎对于cluster tree的控制参数都是全局的,有一些component适用,也一些则不合适。过密的component须要提高盒子的粒度,过于稀疏而且面数不高的,可以减少盒子数。因为,如果植被特别影响性能的时候,可以修改引擎支持让这些参数跟着component走。引起cluster tree盒子的因素有点多,这里主要聊三个。
|
||||
|
||||
- foliage.MaxOcclusionQueriesPerComponent
|
||||
控制每个component的最多盒子数
|
||||
|
||||
- foliage.MinOcclusionQueriesPerComponent
|
||||
控制每个component的最少盒子数
|
||||
|
||||
- foliage.MinInstancesPerOcclusionQuery
|
||||
控制每个盒子最小包含的实例数
|
||||
|
||||
如果这个盒子粒度控制好,在植被比较多的情况下,可以在prepass和basspass省下2MS的预算。
|
||||
|
||||
## SingleLayerWater
|
||||
如果水材质的效果不是用面表达的,是用法线贴图去做的话,可以把材质的mesh换成一个quad,高面的plane,在singlelayerwater里非常耗时。
|
||||
|
||||
## 直接光照
|
||||
### cluster deffer lighting
|
||||
推荐知乎大佬(张亚坤:多光源渲染的版本答案:Cluster Shading)的文章,对于cluster deferred lighting有个介绍,先简单说一下cluster deferred流程。在gather light介段,把视锥体切豆腐,在cs中把光源注入到格子中,然后在cluster deferring shading的发起一个quad的drawcall,每个像素找到对应的grid,从grid中找到对应的light,叠加shading.cluster shading性能肯定是非常好的,优化地方不多,只与采样的buffer大小有关。
|
||||
|
||||
UE5默认是关闭cluster deffered shading的,可以通过r.UseClusteredDeferredShading打开。
|
||||
|
||||
引起不能cluster shading的原因有很多,如产生阴影,有light function,使用light channel,平行光,rect光等。在非cluster shading与unbatch light之间,还有一些light,主要是非shadow,非light function的,主要是rect等,每一个发起一个drawcall,这里消耗不低,能减少就减少一下,把生效距离设置短一点。
|
||||
|
||||
### unbatch light
|
||||
对于unbatch light,主要是lumen scene light和正常的直接光照light,这里就不说了,光照lighting,shadow mask生成,有距离场阴影的也在这里追踪,建议就是交由逻辑层管理,根据不同策略动态开关。
|
||||
@@ -0,0 +1,12 @@
|
||||
---
|
||||
title: Untitled
|
||||
date: 2025-07-08 10:29:19
|
||||
excerpt:
|
||||
tags:
|
||||
rating: ⭐
|
||||
---
|
||||
# Init
|
||||
该组件在ConstructionScript() -> ConstructionScriptFunction() -> AddConstructedCompoents() -> AddUDSPlayerOcclusion中被创建。
|
||||
创建完之后调用UDS_PlayerOcclusion组件的Initialize()完成初始化。
|
||||
|
||||
|
||||
372
03-UnrealEngine/性能优化/UnrealInsight以及其他性能监测工具.md
Normal file
372
03-UnrealEngine/性能优化/UnrealInsight以及其他性能监测工具.md
Normal file
@@ -0,0 +1,372 @@
|
||||
---
|
||||
title: UnrealInsight以及其他性能监测工具
|
||||
date: 2022-08-10 22:18:31
|
||||
excerpt:
|
||||
tags: Profiler
|
||||
rating: ⭐⭐⭐
|
||||
---
|
||||
# 前言
|
||||
目前主要使用的是Unreal Insights。其他工具有:
|
||||
- Stat用于实时显示数据。
|
||||
- GPU Profiler用于显示简单的GPU性能损耗情况。
|
||||
- UnrealFrontend Profiler似乎已经被Unreal Insights代替。
|
||||
|
||||
## Unreal Insights
|
||||
- 官方视频:[UnrealFestOnline2020用Unreal Insights收集、分析及可视化你的数据(官方字幕)](https://www.bilibili.com/video/BV1Ay4y1q7Kj?share_source=copy_web&vd_source=fe8142e8e12816535feaeabd6f6cdc8e)
|
||||
- 官方文档:[UnrealInsights](https://docs.unrealengine.com/4.27/zh-CN/TestingAndOptimization/PerformanceAndProfiling/UnrealInsights/Reference/)
|
||||
- [Networking Insights](https://docs.unrealengine.com/4.27/zh-CN/TestingAndOptimization/PerformanceAndProfiling/UnrealInsights/NetworkingInsights )
|
||||
- [Animation Insights](https://docs.unrealengine.com/4.27/zh-CN/TestingAndOptimization/PerformanceAndProfiling/UnrealInsights/AnimationInsights )
|
||||
- [Slate Insights](https://docs.unrealengine.com/4.27/zh-CN/TestingAndOptimization/PerformanceAndProfiling/UnrealInsights/SlateInsights)
|
||||
- [Animation Insights](https://docs.unrealengine.com/4.27/zh-CN/TestingAndOptimization/PerformanceAndProfiling/UnrealInsights/AnimationInsights/)
|
||||
- [Memory Insights](https://docs.unrealengine.com/5.0/zh-CN/memory-insights-in-unreal-engine/)
|
||||
- 其他知乎文章参考:
|
||||
- [UE4性能分析工具 Unreal Insights](https://zhuanlan.zhihu.com/p/511148107)
|
||||
- [Unreal Insights分析卡顿和降帧](https://zhuanlan.zhihu.com/p/514263195)
|
||||
- [UE UnrealInsights 使用与实现](https://zhuanlan.zhihu.com/p/458086085)
|
||||
|
||||
### 与Profiler 的对比
|
||||
- Profiler 只能记录 CPU 侧的开销信息;Unreal Insights 对 CPU, GPU 的信息都能捕获到
|
||||
- Profiler 能够直接从 Editor 内部打开并检测 Editor 下的性能;Unreal Insights 只能作为独立应用打开,且必须通过添加启动参数才能统计到 Editor 的性能数据
|
||||
- Profiler 对 Game Thread 的瓶颈定位分析粒度更小,能精确定位到开销较大的某个函数
|
||||
- Unreal Insights 作为应用程序的性能更优,能更大程度上减少在本地进行性能检测时造成的额外影响
|
||||
- Unreal Insights 支持远程监测,彻底消除 Profiling 本身对性能检测结果的影响
|
||||
- Unreal Insights 在信息可视化上明显优于 Profiler,有更加具有辨识度的色彩、便捷的操作和良好的交互体验
|
||||
|
||||
### 用法
|
||||
1. 启动UnrealInsights,其路径为`Engine\Binaries\Win64\UnrealInsights.exe`。
|
||||
2. 在工程或者游戏中启用trace命令。
|
||||
3. 此时UnrealInsights会显示连接上的Session,双击这个Session即可查看相关信息。
|
||||
|
||||
>PS.在Windows上开发,打开了UE客户端会自动去连接Unreal Insights。trace的方法默认情况下会生成.utrace文件,可以设置-tracefile=PATH设置生成的路径和文件名,也可以使用.
|
||||
|
||||
#### 客户端
|
||||
非Shipping版本的独立客户端,命令行启动进行数据追踪。命令行需要附带运行工程以及 `-trace=cpu,gpu,frame,log`命令。例如 `D:\UnrealEngine\UE_4.27\Engine\Binaries\Win64\UE4Editor.exe D:\Work\Lyra\Lyra.uproject -game -WINDOWED -ResX=1280 -ResY=720 -trace=cpu,gpu,frame,log`
|
||||
|
||||
编辑器启动的游戏等可以打开命令窗口输入:
|
||||
```text
|
||||
trace.start frame,cpu,gpu | trace.stop 开始停止数据追踪
|
||||
```
|
||||
生成的`.utrace`文件会出现在项目的默认剖析目录中(...`/Saved/Profiling`)
|
||||
|
||||
#### 专用服务器
|
||||
非shipping版本的ds,启动参数添加需要启动参数:
|
||||
```text
|
||||
-tracehost=127.0.0.1 -trace=cpu,frame,bookmark,log,loadtime,file,net,gpu,counters,animation -statnamedevents
|
||||
```
|
||||
会生成.utrace文件. 可以使用-tracefile=PATH 设置文件生成的目录。
|
||||
|
||||
#### 远程追踪
|
||||
凭借Android Debug Bridge (adb),Android工具可通过USB线重定向TCP流量。要在Android设备上连接运行时应用程序,首先指示[adb](https://link.zhihu.com/?target=https%3A//developer.android.com/studio/command-line/adb)经由设备上通过USB建立的TCP连接传递:
|
||||
```text
|
||||
adb.exe reverse tcp:1980 tcp:1980
|
||||
```
|
||||
|
||||
Unreal Insights聆听TCP端口1980。
|
||||
在设备上运行时应连接到 localhost,因此操作系统将通过USB线路由流量。
|
||||
```text
|
||||
-tracehost=127.0.0.1
|
||||
```
|
||||
|
||||
1. 手机端开启开发者模式,数据线连接PC,保持adb连接状态:运行adb reverse tcp:1980 tcp:1980
|
||||
2. PC端启动Unreal Insights,自动监听1980端口
|
||||
3. 设置android手机包的启动参数:通过UE4CommandLine.txt。UE4CommandLine.txt文件中添加:
|
||||
```text
|
||||
-tracehost=127.0.0.1 -trace=cpu,frame,bookmark,log,loadtime,file,net,gpu,counters,animation -statnamedevents
|
||||
```
|
||||
运行`adb push <path_to>\UE4CommandLine.txt /mnt/sdcard/UE4Game/<project_name>/UE4CommandLine.txt` 将文件放入手机项目相关目录。
|
||||
4. 启动app. PC端Unreal Insights上可以看到:手机Trace Session的Status变为LIVE。双击连接即可实时看到数据。同时.utrace文件也会被传到PC端
|
||||
|
||||
### 参数
|
||||
| 命令行选项 | 用途 | 说明 |
|
||||
| ------------------ | ------------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| `-statnamedevents` | `CPUPROFILERTRACE_ENABLED` | 开启指定的追踪事件,若结合 `-trace=cpu`,此选项将激活更多CPU时间事件。 |
|
||||
| `-trace` | `-trace=cpu,frame,bookmark,...` | 追踪指定的Channel |
|
||||
| `-tracehost` | `tracehost=X` | `-tracehost` 的更多详情,请参阅[Unreal Insights介绍](https://docs.unrealengine.com/4.27/zh-CN/TestingAndOptimization/PerformanceAndProfiling/UnrealInsights/Overview) |
|
||||
|
||||
可用追踪的channel包括:
|
||||
- Log
|
||||
- Bookmark
|
||||
- Frame
|
||||
- CPU
|
||||
- GPU
|
||||
- LoadTime
|
||||
- File
|
||||
- Net
|
||||
|
||||
### Android诊断方法
|
||||
- [Gathering Unreal Insights Traces on Android](https://dev.epicgames.com/community/learning/tutorials/eB9R/unreal-engine-gathering-unreal-insights-traces-on-android)
|
||||
- [Android设备上的Unreal Insights](https://dev.epicgames.com/documentation/zh-cn/unreal-engine/how-to-use-unreal-insights-to-profile-android-games-for-unreal-engine)
|
||||
|
||||
可以使用IP直接连接。
|
||||
|
||||
|
||||
## Stat
|
||||
官方文档:[Stat命令](https://docs.unrealengine.com/4.27/zh-CN/TestingAndOptimization/PerformanceAndProfiling/StatCommands/)
|
||||
参考文章:[UE4 性能 - (一)瓶颈定位](https://zhuanlan.zhihu.com/p/438543980)
|
||||
|
||||
用于在屏幕上试试显示各种参数,常用的命令主要有:
|
||||
- Stat Fps
|
||||
- **Stat Unit**
|
||||
- **Frame**: 即一帧所耗费的总时间。
|
||||
- **Game**: CPU Gameplay线程,处理游戏逻辑所耗费的时间。
|
||||
- **Draw**: CPU渲染线程,准备好所有必要的渲染所需的信息,并把它从 _CPU_ 发送给 _GPU_ 所耗费的时间 。
|
||||
- **GPU**: GPU,接收到渲染所需信息之后,将像素最终的表现画在屏幕上的耗时
|
||||
- **Stat UnitGraph**:显示实时图标。
|
||||
- Stat UnitMax
|
||||
- **stat game**:Game逻辑消耗情况。
|
||||
- **stat initviews**:渲染物体剔除损耗情况。
|
||||
- **stat SceneRendering** :Draw Call情况。
|
||||
- stat streaming overview:贴图流占用内存情况。
|
||||
- **stat startfile/stat stopfile**:开始/停止记录性能情况快照,最后会生成*.ue4stats。该文件可以使用[UnrealFrontend Profiler]打开。
|
||||
- **stat slow/stat stopslow**:开始/停止获取实时数据。比如stat slow 0.01 10这将会渲染在过去的10秒内所有运行时间超过10毫秒的循环统计数据。
|
||||
|
||||
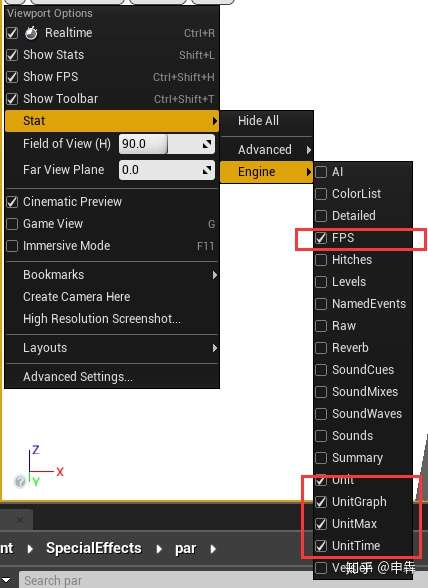
Stat也可以通过点击ViewportOption的Stat进行开启:
|
||||
|
||||
|
||||
## GPU
|
||||
主要的工具:
|
||||
- GPUProfile
|
||||
- 第三方GPU调试工具
|
||||
- RenderDoc
|
||||
- NSight Graphic(N卡)
|
||||
- Radeon GPU Profiler(A卡)
|
||||
- PIX(微软)
|
||||
- GPA(Inter)
|
||||
|
||||
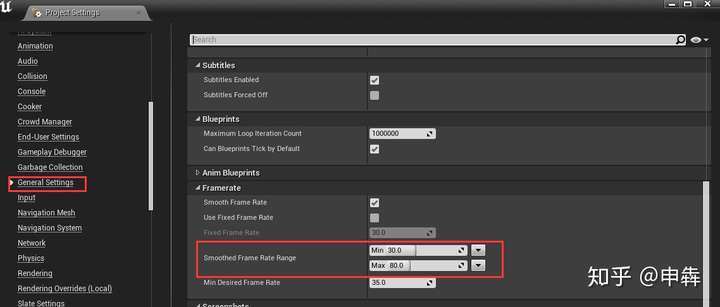
如果有条件还是使用RenderDoc来调试比较好。建议先关闭帧数限制(**- r.VSync** 可以关闭垂直同步):
|
||||
|
||||
|
||||
### GPUProfile
|
||||
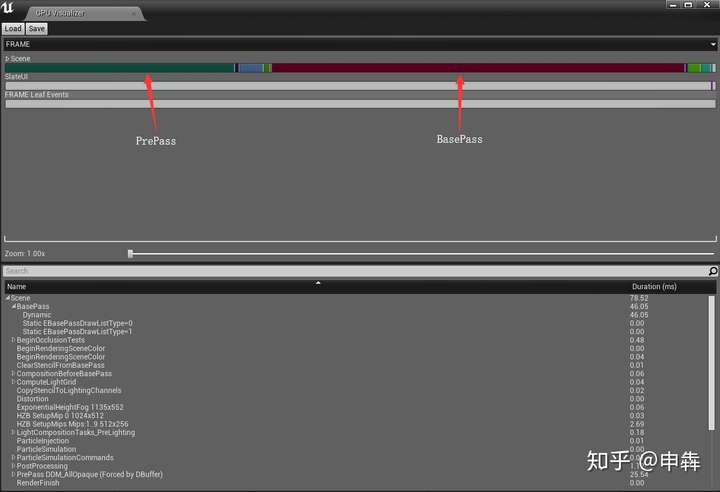
按下**Ctrl+shift+,** 或 者控制台命令: **ProfileGPU**打开:
|
||||
|
||||
|
||||
可以看出影响**GPU**瓶颈最主要的是**BasePass**和**PrePass** 。
|
||||
- **PrePass: RenderPrePass
|
||||
- **Base pass : RenderBasePass / TBasePassDrawingPolicy。**
|
||||
- 渲染不透明和遮盖的材质,向 **GBuffer** 输出材质属性。
|
||||
- 光照图贡献和天空光照也会在此计算并加入场景颜色。
|
||||
- **Lighting :**
|
||||
- 阴影图将对各个光照渲染,光照贡献会累加到场景颜色,并使用标准延迟和平铺延迟着色。光照也会在透明光照体积中累加。
|
||||
- **Fog :**
|
||||
- 雾和大气在延迟通道中对不透明表面进行逐个像素计算。
|
||||
- **Post Processing :**
|
||||
- 多种后期处理效果均通过 GBuffers 应用。透明度将合成到场景中。
|
||||
- 其中 **BasePass 0** =不透明网格。**BasePass 1** =用于Z深度的Alpha蒙版不透明网格。**BasePass Dynamic** =动画顶点,如**Skeletal,GeoCache(Alembic)等**。
|
||||
|
||||
几个值得注意的数据项:
|
||||
- **Base Pass**
|
||||
- **Deferred Decals**
|
||||
- **Lighting**
|
||||
- **SSR(环境反射)**
|
||||
- **Translucency(半透明)**
|
||||
- **Postprocessing(后期处理效果)**
|
||||
- **Particle(粒子)**
|
||||
|
||||
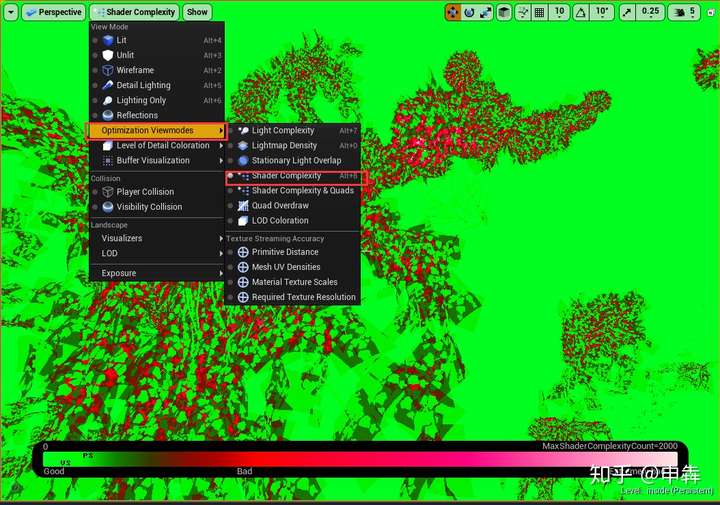
### 材质复杂度
|
||||
材质复杂程度在这里可以查看,**越红的越消耗**,原则上减少使用点动画和曲面细分等一些效果。**红色:**意味着性能消耗非常高 绿色:意味着性能消耗最低半透明:意味着增加性能消耗
|
||||
|
||||
|
||||
## CPU
|
||||
### Game Thread
|
||||
Game Thread 造成的开销,基本可以归因于 C++ 和蓝图的逻辑处理,瓶颈常见于Tick 和高复杂度逻辑。大量物体同时 Tick 会严重影响 Game Thread 的耗时。
|
||||
针对Tick可使用:
|
||||
- **stat game**:显示 Tick 的耗时情况
|
||||
- **dumpticks**:可将所有正在 _tick_ 的 _actor_ 打印到 _log_ 中
|
||||
- dumpticks grouped
|
||||
- **stat tickables**
|
||||
- **listtimers**
|
||||
- **stat uobjects**
|
||||
- [[#MOVING SCENE COMPONENTS]]
|
||||
|
||||
复杂逻辑:需要借助 Unreal Frontend Profiler / Unreal Insights 等工具对游戏逻辑中开销较大的代码进行定位。
|
||||
### LandscapeSubsystem Tick
|
||||
主要是在更新Grass。在非编辑器下的 Game 模式,可以通过 Console Variable `grass.TickInterval` 来设置更新间隔,其数值会被 clamp 在 1 到 60 之间。
|
||||
或者极端点的直接`grass.Enable 0`
|
||||
|
||||
UE5.2 LandscapeGrass.cpp
|
||||
```c++
|
||||
static void GrassCVarSinkFunction()
|
||||
{
|
||||
static float CachedGrassDensityScale = 1.0f;
|
||||
float GrassDensityScale = GGrassDensityScale;
|
||||
|
||||
if (FApp::IsGame())
|
||||
{ ALandscapeProxy::SetGrassUpdateInterval(FMath::Clamp<int32>(GGrassTickInterval, 1, 60));
|
||||
}
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
### Draw Thread (Rendering Thread)
|
||||
Draw Thread 的主要开销来源于 **Visibility Culling** 和 **Draw Call**。
|
||||
|
||||
**Visibility Culling** 会基于深度缓存(Depth Buffer) 信息,剔除位于相机的视锥体(Frustum)之外的物体和被遮挡住(Occluded)的物体,当游戏世界中可见的物体过多,剔除所需的计算量也将变大,导致耗时过长
|
||||
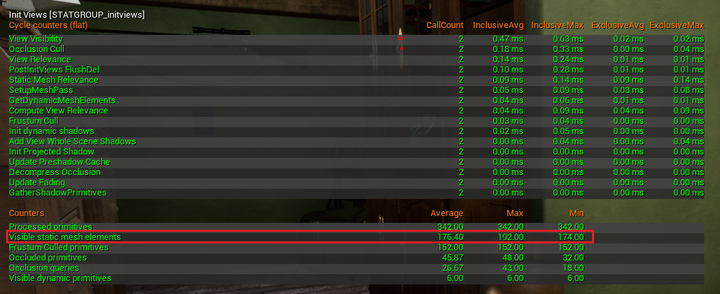
- **stat initviews**:显示 Visibility Culling 的耗时情况,同时还能显示当前场景中可见的 Static Mesh 的数量(Visible Static Mesh Elements)
|
||||
|
||||
|
||||
|
||||
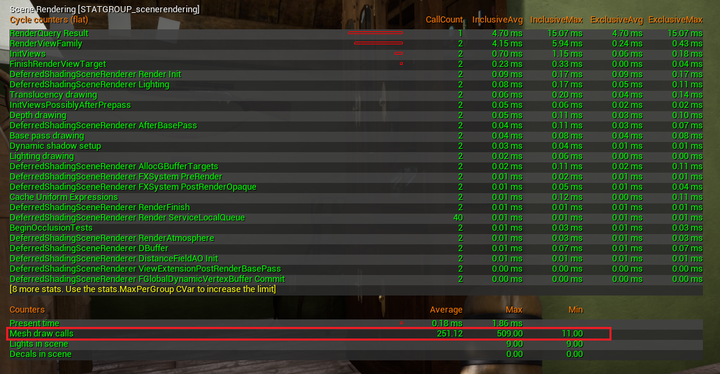
**Draw Call**为CPU向GPU提交渲染数据的过程。在UE中只要将多边形赋予相同的Materials,引擎将会自动合并Batch,这个过程叫做**合批**。合批工具一般会把相同ShaderModel的材质合并到一起来实现,具体就是把多个材质所用到的贴图合并到一起,在一个材质中使用。并且使用一个Index来控制当前材质。
|
||||
|
||||
- **stat SceneRendering** 可查看 Mesh Draw Call 的数量
|
||||
- 相比于面数,**Draw Call** 对性能开销的影响要大得多
|
||||
|
||||
|
||||
### GPU Thread
|
||||
- 顶点瓶颈(**Vertex-bound**)
|
||||
- Dynamic Shadow
|
||||
- 目前动态阴影(Dynamic Shadow)的生成主要依赖 **Shadow Mapping**,Shadow Mapping 每生成一次阴影需要进行两次光栅化,因此当顶点数过多(可能源于多边形数量巨大,也可能源于不适当的曲面细分) 时,Dynamic Shadow 将成为 GPU 在光栅化阶段的一大性能瓶颈
|
||||
- **ShowFlag.DynamicShadows 0**: 使用该指令可关闭场景内的动态阴影(0表示关闭,1表示开启),可在开启和关闭两种状态间反复切换,查看卡顿情况是否发生明显变化,以此判断 Dynamic Shadow 是否确实造成了巨大开销
|
||||
- 着色瓶颈(**Pixel-bound**)
|
||||
- 运行指令 **r.ScreenPercentage 50**,表示将渲染的像素数量**减半**_(也可替换成其他 0-100 之间的数)_,观察卡顿现象是否明显减缓,以此判断瓶颈是否 _Pixel-bound_
|
||||
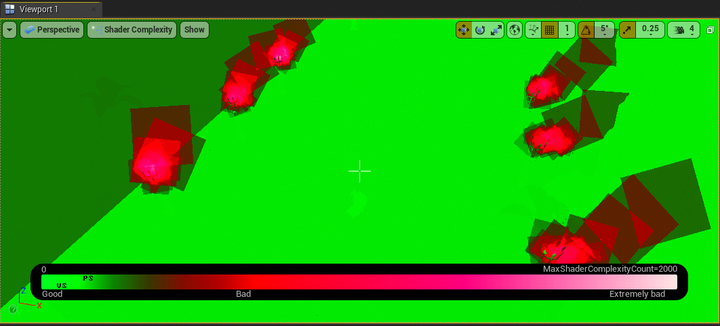
- **Shader Complexity**
|
||||
- 显示对每一个像素所执行的着色指令数量,数量越多,消耗越大
|
||||
- 场景中存在过多的半透明物体(Translucent Object),会显著增加 Pixel Shader 的计算压力,使用 **stat SceneRendering** 可查看 Translucency 的消耗情况;使用 **ShowFlag.Translucency 0** 来关闭(0表示关闭,1表示开启)所有半透明效果
|
||||
- 当Shader的实现逻辑过于复杂或低效时,也会导致较高的 Shader Complexity
|
||||
- 在 Viewport 中选择 Optimization Viewmodes → Shader Complexity,可视化 Shader 造成的开销
|
||||
|
||||
|
||||
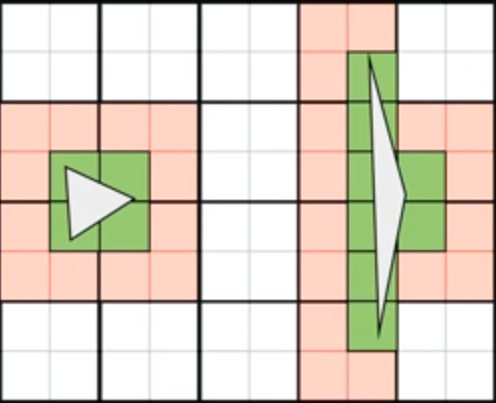
- **Quad Overdraw**
|
||||
- 着色期间 _GPU_ 的大部分操作不是基于单个像素,而是一块一块地绘制,这个块就叫 _Quad_,是由 4 个像素 _(2 × 2)_ 组成的像素块
|
||||
- 当模型存在较多**狭长、细小的三角形**时,有效面积较小,但可能占用了很多 _Quad_,_Quad_ 被多次重复绘制,会导致大量像素参与到无意义的计算中,引起不必要的性能开销
|
||||
|
||||
|
||||
- 进入 _Optimization Viewmodes → Quad Overdraw_,显示 _GPU_ 对每个 _Quad_ 的绘制次数
|
||||

|
||||
|
||||
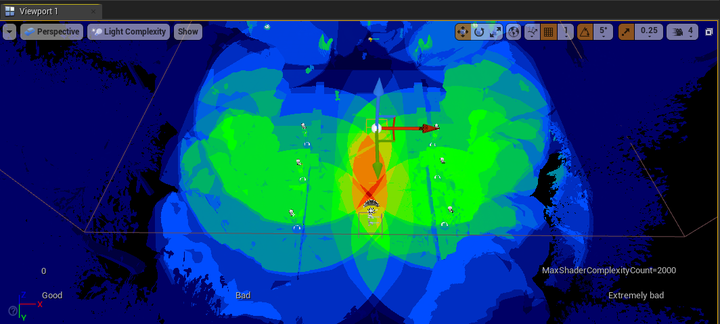
- **Light Complexity**
|
||||
- 场景内的动态光源(Dynamic Lights)数量过多时,会产生大量动态阴影(Dynamic Shadow)_,如上述所说,容易引起较大开销
|
||||
- 动态光源的半径过大,导致多个光源的范围出现大量交叠,也可能导致严重的 _Overdraw_ 问题
|
||||
- 进入 _Optimization Viewmodes → Light Complexity_,查看灯光引起的性能开销
|
||||
|
||||
|
||||
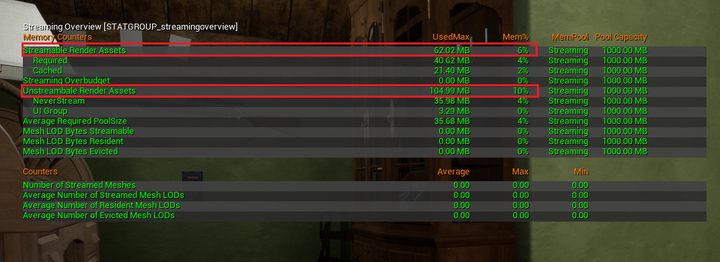
- 内存(**Memory-bound**)_引起的瓶颈
|
||||
- 有时性能瓶颈还在于过高的内存占用,其中最常见的是大量的纹理(Texture)_加载和采样
|
||||
- 使用 **stat streaming overview**,查看当前纹理对内存的占用情况
|
||||
- 对于纹理的优化,后续将另开新篇加以详细介绍
|
||||
|
||||
|
||||
## 内存
|
||||
- MEMREPORT -full
|
||||
- Runs a number of individual commands for memory profiling
|
||||
- obj list class=
|
||||
- Example: obj list class=AnimSequence
|
||||
- Only in Packaged Builds
|
||||
- Example: AnimSequence twice as large in editor builds.
|
||||
|
||||
这样就就可以查看指定Object的内存占用情况。
|
||||
|
||||
## COLLISION & PHYSICS
|
||||
- Unreal configured to work out of the box.
|
||||
- “Collision Enabled” => Physics + Query
|
||||
- Most things require just ‘QueryOnly’
|
||||
- Disable on components players can’t reach or interact with.
|
||||
- Profiling
|
||||
- stat physics, stat collision
|
||||
- obj list class=BodySetup
|
||||
- show CollisionPawn, show CollisionVisibility
|
||||
- Tip: Landscape may use lower collision MIPs
|
||||
|
||||
## MOVING SCENE COMPONENTS
|
||||
移动场景组件可能会造成一些性能问题,需要注意以下几点:
|
||||
- Move/Rotate only once per frame
|
||||
- **Disable Collision & GenerateOverlaps=False**
|
||||
- AutoManageAttachment
|
||||
- Audio & Niagara
|
||||
- Profiling
|
||||
- stat component
|
||||
|
||||
### MOVING COMPONENTS - BOUNDS
|
||||
- ***UseAttachParentBound=True***
|
||||
- Skips “CalcBounds”
|
||||
- 检查命令:show Bounds / showflag.bounds 1
|
||||
|
||||
蓝图中勾选***UseAttachParentBound***,以此跳过计算CalcBounds的问题。
|
||||
## UnrealFrontend Profiler
|
||||
官方文档:[Profiler Tool](https://docs.unrealengine.com/4.27/zh-CN/TestingAndOptimization/PerformanceAndProfiling/Profiler/)
|
||||
其他参考文章:
|
||||
- [UE4性能分析工具 UnrealFrontend Profiler](https://zhuanlan.zhihu.com/p/510862140)
|
||||
- [UE4 性能 - (二) 性能分析工具: Unreal Frontend Profiler](https://zhuanlan.zhihu.com/p/441501920)
|
||||
|
||||
### 常见操作流程
|
||||
- 运行游戏,切换到 **Profiler** 界面
|
||||
- **Main Toolbar** 中点击 **Data Preview** 开始预览性能数据
|
||||
- 关注 **Data Graph Full** 内是否出现明显尖峰,如果有并希望马上查看原因,则再次点击 **Data Preview** 停止预览
|
||||
- 拖动 **Data Graph Full** 中的绿色滑窗至尖峰处,开始观察 **Data Graph** 界面,准确定位导致开销陡升发生在哪一帧或哪一小段
|
||||
- 在 **Data Graph** 中选择一段时长范围,此时 **Event Graph** 将显示这段时长内各方法的耗时情况,按降序排列
|
||||
- 在 **Event Graph** 的 **Main Event Graph** 区域展开条目层级,根据 **Function Details** 区域显示的信息,一级级深入定位到具体的方法上
|
||||
|
||||
### 游戏线程分析
|
||||
查看游戏线程的性能表现的最佳工具是使用统计数据分析程序。
|
||||
在控制台输入“**stat startfile**”来启动分析
|
||||
等10秒左右输入“**stat stopfile**”收集这10秒的平均值当然也可以等更多的时间。
|
||||
在路径**Saved/Profiling/UnrealStats**下,会有关于您项目文件夹的**ue4stats**文件。
|
||||
也可以用“**stat slow**”来获取实时的报告,它可以通过报告运行一帧中特定时间段**(默认10毫秒**)来逐步定位帧停顿的位置。
|
||||
运行速度较慢的数据将会在**HUD**上显示一段时间,从而判断性能波动。
|
||||
“**Stat stopslow**”来关闭它。
|
||||
参数以秒为单位(所以10ms也就是0.01秒)参数可设置持续的时间,默认值是**10**秒。
|
||||
**例:**STAT SLOW 0.01 10这将会渲染在过去的10秒内所有运行时间超过10毫秒的循环统计数据。
|
||||
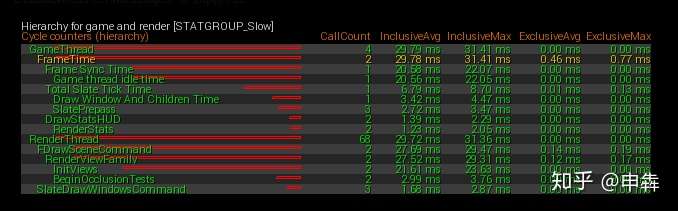
|
||||
|
||||
现在我们需要分析,需要打开编辑器中的**Session Frontend**(会话前端)
|
||||
|
||||
|
||||
当您打开了会话前端选项卡后,您需要切换到**Profiler**(分析程序)的小选项卡。在该处,您可以选择载入您最近捕获的**ue4stats**分析文件。
|
||||

|
||||
|
||||
加载后会这样显示
|
||||
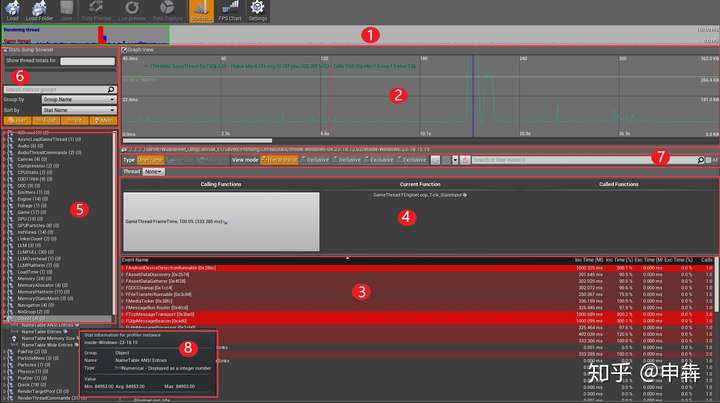
|
||||
|
||||
1. 渲染线程vs游戏线程的简图
|
||||
- 根据CPU逻辑与渲染的关系,一眼你就会知道你是否是CPU受限的,或者它是否是与游戏相关的且花费最多性能的逻辑。
|
||||
2. 抓取期间的整个CPU加载的简图
|
||||
- 在这里,你可以沿着时间线单击任何部分来观察对应帧的CPU分析,或者你可以单击、拖拽来选择帧的范围并且查看均值。根据你这里的选择,函数时间(3)的层级列表中的分析数据会改变。
|
||||
3. 调用的不同函数和所花时间的层级列表
|
||||
- 花费时间最长的函数排在顶端。花费最多时间的函数以**红色**显示,其它用**黑色**显示。你可以通过单击左侧三角来展开对应层,你可以看到这个函数调用过程的分解以及执行花费的时间。
|
||||
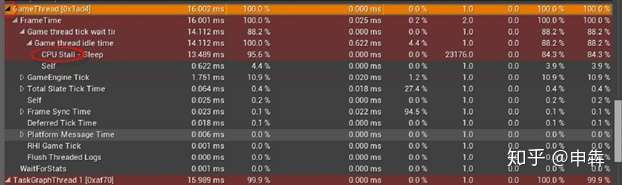
|
||||
**注意这里的CPU停转是CPU闲置等待其它线程结束的时间**
|
||||
4. 如果你在函数时间(3)的层级列表中选择了特定的函数,你可以看到这里的显示变化,这里显示了什么函数调用了这个函数,以及该函数调用了哪些函数,同时可以看到这些调用和被调用函数执行时间的比例。
|
||||
5. 左侧面板展示了stats和stat组。顶层是stat组,你可以展开它查看内部的独立stat。这些stat可以是整型、浮点型数字或者内存,你可以控制哪些显示在stat过滤器面板(6)中。如果你鼠标停留在一个stat上,会弹出该stat的分析信息(8)。
|
||||
6. 在这里你可以通过搜索想要的stat、改变分组和排序、隐藏/显示不同类型的stat(浮点/整型/内存)以及启用/禁用层级视图控制stat面板的显示(5)。
|
||||
7. 这些控件用于显示函数时间的层级列表和所选函数的分解信息(4)
|
||||
1. 类型
|
||||
- 如果在图像视图中你只选择了一帧(2),你唯一的选择就是显示信息那帧,但是如果你选择了一系列帧,你可以选择是否显示平均时间或者花费的最长时间。
|
||||
2. 视图模式
|
||||
- 这会改变函数时间分层的层级列表视图(3),或者改变单纯的函数列表,里面包括这些函数的子程序包括的或排除的时间。
|
||||
3. 向前、向后按钮可以让你在图像视图的不同部分之间跳转(2)
|
||||
- 所有你可以看到一系列信息,之后缩小你的选择范围直到一个帧,然后用这些按钮来在两者之间切换。下拉箭头显示了之前的选择。
|
||||
4. 这里的火焰按钮是用来展开你当前选择函数的时间层级列表的(3)
|
||||
- 用来查找花费最多时间的路径,它也会用一个小火焰图标来标识该路径。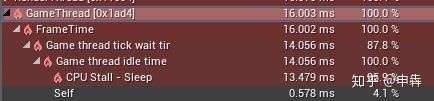
|
||||
8. 鼠标在stat面板(5)的一个stat上面停留时,会显示关于该stat的分析信息,最重要的是最小值、平均值和最大值:
|
||||
>这里我们只关注几个选项,展开**GameThread(游戏线程)**项目,然后往下拉,直到您看到超过几毫秒的“**Inc Time**”(包含时间)条目,而且其不包含许多子项或不包含任何子项。
|
||||
同时关注一下“**Calls**”(调用)数列,它显示了每帧调用的统计数据的平均次数。
|
||||
不要被“**CPU Stall**”(CPU停滞时间)项目弄糊涂了。
|
||||
它们显示的是线程等待处理其他内容时所花费的时间,所以不是主要数据,而且仅仅会在帧频率受限或者游戏进程不为瓶颈时才会显示出来。
|
||||
|
||||
- 还有一个重要项目**TickFunctionTask**。
|
||||
>此项目下是正在更新的每个**actor**和组件。
|
||||
一般来说,降低每帧更新的**actor**和组件的数量都可以很好地加速游戏。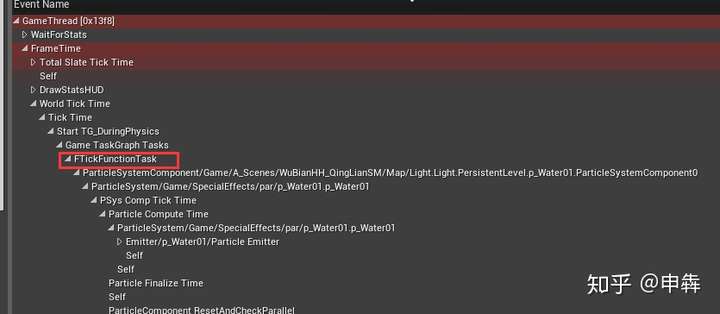
|
||||
- 另一个要关注的是**BlueprintTime(蓝图时间)**
|
||||
>找到这个值的最佳方法是切换到包含(合并)视图并在列表中找到它。
|
||||
这样就可以把所有的**BlueprintTime(蓝图时间**)条目组合到单一行中。
|
||||
如果您选择**BlueprintTime(蓝图时间)**,然后切换回层次视图,则其会选择所有蓝图代码被执行的位置,这样能让您很好地了解花费时间进行处理的位置及其位于哪个蓝图中。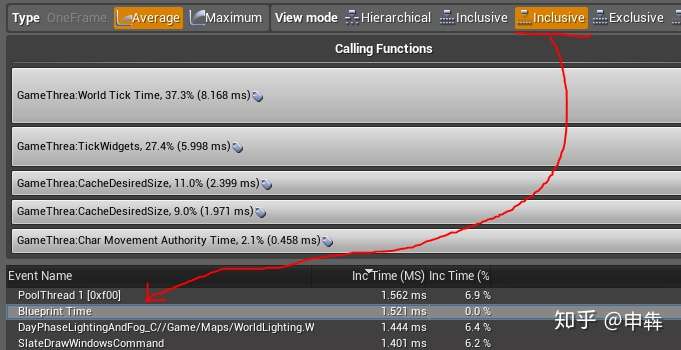
|
||||
- 另一个常见的问题位置是**TickWidgets(更新控件)**
|
||||
>如果这个统计数据值很高,这表示您可能同时显示了太多控件,或者这些控件上的属性代理过于复杂。
|
||||
一些**slate**属性,比如可见性,可能会在每帧被调用好几次,这样它们的值必须要小而且能及时返回。
|
||||
|
||||
**您是不是在游戏中有很多骨架网格物体?**
|
||||
>**SkinnedMeshComp更新时间**有时也会消耗很多系统资源
|
||||
请尝试降低显示在分析文件中的骨架中的骨骼数量,或者降低动画蓝图的复杂度。
|
||||
如果您不需要在无法看到骨架网格物体时更新动画,请考虑将骨架网格物体组件上的**MeshComponentUpdateFlag(网格物体组件更新标识)**正确设置为**OnlyTickPoseWhenRendered(仅在渲染时更新姿势)**。
|
||||
请注意,将此标识设置为**AnimNotifies(动画通知)**将使得这些网格物体不被渲染时不再对其进行触发。
|
||||
|
||||
## 打包项目调试
|
||||
可以参考[[打包项目的Debug方法]] 。
|
||||
|
||||
## 资产优化工具
|
||||
- MergeActors:合批工具。
|
||||
- DeviceProfile:针对不同设备使用不同的渲染参数。
|
||||
- **LOD**
|
||||
- ModelLOD
|
||||
- MaterialLOD
|
||||
- ParticleLOD
|
||||
- 粒子裁剪工具:将粒子透明部分裁剪掉,减少重叠区域。
|
||||
8
03-UnrealEngine/性能优化/c++内存泄漏分析工具.md
Normal file
8
03-UnrealEngine/性能优化/c++内存泄漏分析工具.md
Normal file
@@ -0,0 +1,8 @@
|
||||
---
|
||||
title: c++内存泄漏分析工具
|
||||
date: 2024-02-04 21:15:26
|
||||
excerpt:
|
||||
tags:
|
||||
rating: ⭐
|
||||
---
|
||||
https://github.com/dpull/tracing_malloc?tab=readme-ov-file
|
||||
14
03-UnrealEngine/性能优化/使用3D Sprites进行远景优化.md
Normal file
14
03-UnrealEngine/性能优化/使用3D Sprites进行远景优化.md
Normal file
@@ -0,0 +1,14 @@
|
||||
---
|
||||
title: 使用3D Sprites进行远景优化
|
||||
date: 2022-09-14 14:37:20
|
||||
excerpt:
|
||||
tags:
|
||||
rating: ⭐
|
||||
---
|
||||
## 前言
|
||||
官方文档:https://docs.unrealengine.com/4.27/en-US/RenderingAndGraphics/RenderToTextureTools/3/
|
||||
|
||||
## 其他
|
||||
除了远景的树木,还可以用来做云的效果。月下幻影做的效果演示。
|
||||

|
||||

|
||||
15
03-UnrealEngine/性能优化/移动端/UE5移动端优化方法与实践笔记.md
Normal file
15
03-UnrealEngine/性能优化/移动端/UE5移动端优化方法与实践笔记.md
Normal file
@@ -0,0 +1,15 @@
|
||||
---
|
||||
title: Untitled
|
||||
date: 2025-06-09 18:05:03
|
||||
excerpt:
|
||||
tags:
|
||||
rating: ⭐
|
||||
---
|
||||
# 前言
|
||||
- [移动游戏的性能优化 | 材质优化篇 - 腾讯游戏学堂的文章](https://zhuanlan.zhihu.com/p/688098852)
|
||||
- [UE4移动端性能分析](https://zhuanlan.zhihu.com/p/1034898589)
|
||||
|
||||
# 合批
|
||||
## UE4移动端合批
|
||||
- [UE4 4.23 移动端渲染的Dynamic Instancing分析(上)](https://zhuanlan.zhihu.com/p/99789976)
|
||||
- [UE4 4.23 移动端渲染的Dynamic Instancing分析(下)](https://zhuanlan.zhihu.com/p/100224369)
|
||||
Reference in New Issue
Block a user