Init
This commit is contained in:
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
@@ -0,0 +1,737 @@
|
||||
---
|
||||
title: Untitled
|
||||
date: 2024-02-04 12:57:56
|
||||
excerpt:
|
||||
tags:
|
||||
rating: ⭐
|
||||
---
|
||||
# 前言
|
||||
原文地址:https://www.cnblogs.com/timlly/p/15156626.html
|
||||
|
||||
# 概念
|
||||
- FRenderResource:是渲染线程的渲染资源基础父类,实际的数据和逻辑由子类实现。可以认为是渲染线程中承载**CPU相关相关渲染的载体**。
|
||||
- 比如输入的顶点数据、顶点Index数据、贴图数据等。
|
||||
- FRHIResource:抽象了GPU侧的资源,也是众多RHI资源类型的父类。可以认为是承载**显卡API相关资源的载体**。
|
||||
- 比如TextureSampler、TextureObject等。
|
||||
- FRHICommand:其父类为**FRHICommandBase**结构体。其含有**FRHICommandBase* Next**用来保存下一个Command的指针,所以存储他的结构为**链表**。
|
||||
- 含有接口:void void ExecuteAndDestruct(FRHICommandListBase& CmdList, FRHICommandListDebugContext& DebugContext)。执行完就销毁。
|
||||
- UE使用**FRHICOMMAND_MACRO**宏来快速定义各种RHICommand。主要功能包含:
|
||||
- 数据和资源的设置、更新、清理、转换、拷贝、回读。
|
||||
- 图元绘制。
|
||||
- Pass、SubPass、场景、ViewPort等的开始和结束事件。
|
||||
- 栅栏、等待、广播接口。
|
||||
- 光线追踪。
|
||||
- Slate、调试相关的命令。
|
||||
- FRHICommandList:是**RHI的指令队列**,用来管理、执行一组FRHICommand的对象。
|
||||
- 其子类有**FRHICommandListImmediate**(立即执行队列)、FRHIComputeCommandList_RecursiveHazardous与TRHIComputeCommandList_RecursiveHazardous(命令列表的递归使用)
|
||||
- IRHICommandContext:是RHI的命令上下文接口类,定义了一组图形API相关的操作。在可以并行处理命令列表的平台上,它是一个单独的对象类。
|
||||
- 主要的接口函数有:
|
||||
- 派发ComputeShader
|
||||
- 渲染查询(可见性?)
|
||||
- 相关开始/结束函数。
|
||||
- 设置数据(Viewport、GraphicsPipelineState等)
|
||||
- 设置ShadserParameter
|
||||
- 绘制图元
|
||||
- 纹理拷贝/更新
|
||||
- Raytracing
|
||||
- IRHICommandContext的接口和FRHICommandList的接口高度相似且重叠。IRHICommandContext还有许多子类:
|
||||
- IRHICommandContextPSOFallback:不支持真正的图形管道的RHI命令上下文。
|
||||
- FNullDynamicRHI:空实现的动态绑定RHI。
|
||||
- FOpenGLDynamicRHI:OpenGL的动态RHI。
|
||||
- FD3D11DynamicRHI:D3D11的动态RHI。
|
||||
- FMetalRHICommandContext:Metal平台的命令上下文。
|
||||
- FD3D12CommandContextBase:D3D12的命令上下文。
|
||||
- FVulkanCommandListContext:Vulkan平台的命令队列上下文。
|
||||
- FEmptyDynamicRHI:动态绑定的RHI实现的接口。
|
||||
- FValidationContext:校验上下文。
|
||||
- IRHICommandContextContainer:IRHICommandContextContainer就是包含了IRHICommandContext对象的类型。相当于存储了一个或一组命令上下文的容器,以支持并行化地提交命令队列,只在D3D12、Metal、Vulkan等现代图形API中有实现。
|
||||
- D3D12存储了FD3D12Adapter* Adapter、FD3D12CommandContext* CmdContext、 FD3D12CommandContextRedirector* CmdContextRedirector。
|
||||
- FDynamicRHI:FDynamicRHI是由动态绑定的RHI实现的接口,它定义的接口和CommandList、CommandContext比较相似。
|
||||
- 代码详见[[#FDynamicRHI]]
|
||||
- FRHICommandListExecutor:负责将**Renderer层的RHI中间指令转译(或直接调用)到目标平台的图形API**,它在RHI体系中起着举足轻重的作用。
|
||||
- FParallelCommandListSet:用于实现并行渲染。使用案例详见[[#FParallelCommandListSet]]。目前5.3只有下面2个子类:
|
||||
- FRDGParallelCommandListSet
|
||||
- FShadowParallelCommandListSet
|
||||
|
||||
## FDynamicRHI
|
||||
```c++
|
||||
class RHI_API FDynamicRHI
|
||||
{
|
||||
public:
|
||||
virtual ~FDynamicRHI() {}
|
||||
|
||||
virtual void Init() = 0;
|
||||
virtual void PostInit() {}
|
||||
virtual void Shutdown() = 0;
|
||||
|
||||
void InitPixelFormatInfo(const TArray<uint32>& PixelFormatBlockBytesIn);
|
||||
|
||||
// ---- RHI接口 ----
|
||||
|
||||
// 下列接口要求FlushType: Thread safe
|
||||
virtual FSamplerStateRHIRef RHICreateSamplerState(const FSamplerStateInitializerRHI& Initializer) = 0;
|
||||
virtual FRasterizerStateRHIRef RHICreateRasterizerState(const FRasterizerStateInitializerRHI& Initializer) = 0;
|
||||
virtual FDepthStencilStateRHIRef RHICreateDepthStencilState(const FDepthStencilStateInitializerRHI& Initializer) = 0;
|
||||
virtual FBlendStateRHIRef RHICreateBlendState(const FBlendStateInitializerRHI& Initializer) = 0;
|
||||
|
||||
// 下列接口要求FlushType: Wait RHI Thread
|
||||
virtual FVertexDeclarationRHIRef RHICreateVertexDeclaration(const FVertexDeclarationElementList& Elements) = 0;
|
||||
virtual FPixelShaderRHIRef RHICreatePixelShader(TArrayView<const uint8> Code, const FSHAHash& Hash) = 0;
|
||||
virtual FVertexShaderRHIRef RHICreateVertexShader(TArrayView<const uint8> Code, const FSHAHash& Hash) = 0;
|
||||
virtual FHullShaderRHIRef RHICreateHullShader(TArrayView<const uint8> Code, const FSHAHash& Hash) = 0;
|
||||
virtual FDomainShaderRHIRef RHICreateDomainShader(TArrayView<const uint8> Code, const FSHAHash& Hash) = 0;
|
||||
virtual FGeometryShaderRHIRef RHICreateGeometryShader(TArrayView<const uint8> Code, const FSHAHash& Hash) = 0;
|
||||
virtual FComputeShaderRHIRef RHICreateComputeShader(TArrayView<const uint8> Code, const FSHAHash& Hash) = 0;
|
||||
|
||||
// FlushType: Must be Thread-Safe.
|
||||
virtual FRenderQueryPoolRHIRef RHICreateRenderQueryPool(ERenderQueryType QueryType, uint32 NumQueries = UINT32_MAX);
|
||||
inline FComputeFenceRHIRef RHICreateComputeFence(const FName& Name);
|
||||
|
||||
virtual FGPUFenceRHIRef RHICreateGPUFence(const FName &Name);
|
||||
virtual void RHICreateTransition(FRHITransition* Transition, ERHIPipeline SrcPipelines, ERHIPipeline DstPipelines, ERHICreateTransitionFlags CreateFlags, TArrayView<const FRHITransitionInfo> Infos);
|
||||
virtual void RHIReleaseTransition(FRHITransition* Transition);
|
||||
|
||||
// FlushType: Thread safe.
|
||||
virtual FStagingBufferRHIRef RHICreateStagingBuffer();
|
||||
virtual void* RHILockStagingBuffer(FRHIStagingBuffer* StagingBuffer, FRHIGPUFence* Fence, uint32 Offset, uint32 SizeRHI);
|
||||
virtual void RHIUnlockStagingBuffer(FRHIStagingBuffer* StagingBuffer);
|
||||
|
||||
// FlushType: Thread safe, but varies depending on the RHI
|
||||
virtual FBoundShaderStateRHIRef RHICreateBoundShaderState(FRHIVertexDeclaration* VertexDeclaration, FRHIVertexShader* VertexShader, FRHIHullShader* HullShader, FRHIDomainShader* DomainShader, FRHIPixelShader* PixelShader, FRHIGeometryShader* GeometryShader) = 0;
|
||||
// FlushType: Thread safe
|
||||
virtual FGraphicsPipelineStateRHIRef RHICreateGraphicsPipelineState(const FGraphicsPipelineStateInitializer& Initializer);
|
||||
|
||||
// FlushType: Thread safe, but varies depending on the RHI
|
||||
virtual FUniformBufferRHIRef RHICreateUniformBuffer(const void* Contents, const FRHIUniformBufferLayout& Layout, EUniformBufferUsage Usage, EUniformBufferValidation Validation) = 0;
|
||||
virtual void RHIUpdateUniformBuffer(FRHIUniformBuffer* UniformBufferRHI, const void* Contents) = 0;
|
||||
|
||||
// FlushType: Wait RHI Thread
|
||||
virtual FIndexBufferRHIRef RHICreateIndexBuffer(uint32 Stride, uint32 Size, uint32 InUsage, ERHIAccess InResourceState, FRHIResourceCreateInfo& CreateInfo) = 0;
|
||||
virtual void* RHILockIndexBuffer(FRHICommandListImmediate& RHICmdList, FRHIIndexBuffer* IndexBuffer, uint32 Offset, uint32 Size, EResourceLockMode LockMode);
|
||||
virtual void RHIUnlockIndexBuffer(FRHICommandListImmediate& RHICmdList, FRHIIndexBuffer* IndexBuffer);
|
||||
virtual void RHITransferIndexBufferUnderlyingResource(FRHIIndexBuffer* DestIndexBuffer, FRHIIndexBuffer* SrcIndexBuffer);
|
||||
|
||||
// FlushType: Wait RHI Thread
|
||||
virtual FVertexBufferRHIRef RHICreateVertexBuffer(uint32 Size, uint32 InUsage, ERHIAccess InResourceState, FRHIResourceCreateInfo& CreateInfo) = 0;
|
||||
// FlushType: Flush RHI Thread
|
||||
virtual void* RHILockVertexBuffer(FRHICommandListImmediate& RHICmdList, FRHIVertexBuffer* VertexBuffer, uint32 Offset, uint32 SizeRHI, EResourceLockMode LockMode);
|
||||
virtual void RHIUnlockVertexBuffer(FRHICommandListImmediate& RHICmdList, FRHIVertexBuffer* VertexBuffer);
|
||||
// FlushType: Flush Immediate (seems dangerous)
|
||||
virtual void RHICopyVertexBuffer(FRHIVertexBuffer* SourceBuffer, FRHIVertexBuffer* DestBuffer) = 0;
|
||||
virtual void RHITransferVertexBufferUnderlyingResource(FRHIVertexBuffer* DestVertexBuffer, FRHIVertexBuffer* SrcVertexBuffer);
|
||||
|
||||
// FlushType: Wait RHI Thread
|
||||
virtual FStructuredBufferRHIRef RHICreateStructuredBuffer(uint32 Stride, uint32 Size, uint32 InUsage, ERHIAccess InResourceState, FRHIResourceCreateInfo& CreateInfo) = 0;
|
||||
// FlushType: Flush RHI Thread
|
||||
virtual void* RHILockStructuredBuffer(FRHICommandListImmediate& RHICmdList, FRHIStructuredBuffer* StructuredBuffer, uint32 Offset, uint32 SizeRHI, EResourceLockMode LockMode);
|
||||
virtual void RHIUnlockStructuredBuffer(FRHICommandListImmediate& RHICmdList, FRHIStructuredBuffer* StructuredBuffer);
|
||||
|
||||
// FlushType: Wait RHI Thread
|
||||
virtual FUnorderedAccessViewRHIRef RHICreateUnorderedAccessView(FRHIStructuredBuffer* StructuredBuffer, bool bUseUAVCounter, bool bAppendBuffer) = 0;
|
||||
// FlushType: Wait RHI Thread
|
||||
virtual FUnorderedAccessViewRHIRef RHICreateUnorderedAccessView(FRHITexture* Texture, uint32 MipLevel) = 0;
|
||||
// FlushType: Wait RHI Thread
|
||||
virtual FUnorderedAccessViewRHIRef RHICreateUnorderedAccessView(FRHITexture* Texture, uint32 MipLevel, uint8 Format);
|
||||
|
||||
(......)
|
||||
|
||||
// RHI帧更新,须从主线程调用,FlushType: Thread safe
|
||||
virtual void RHITick(float DeltaTime) = 0;
|
||||
// 阻塞CPU直到GPU执行完成变成空闲. FlushType: Flush Immediate (seems wrong)
|
||||
virtual void RHIBlockUntilGPUIdle() = 0;
|
||||
// 开始当前帧,并确保GPU正在积极地工作 FlushType: Flush Immediate (copied from RHIBlockUntilGPUIdle)
|
||||
virtual void RHISubmitCommandsAndFlushGPU() {};
|
||||
|
||||
// 通知RHI准备暂停它.
|
||||
virtual void RHIBeginSuspendRendering() {};
|
||||
// 暂停RHI渲染并将控制权交给系统的操作, FlushType: Thread safe
|
||||
virtual void RHISuspendRendering() {};
|
||||
// 继续RHI渲染, FlushType: Thread safe
|
||||
virtual void RHIResumeRendering() {};
|
||||
// FlushType: Flush Immediate
|
||||
virtual bool RHIIsRenderingSuspended() { return false; };
|
||||
|
||||
// FlushType: called from render thread when RHI thread is flushed
|
||||
// 仅在FRHIResource::FlushPendingDeletes内的延迟删除之前每帧调用.
|
||||
virtual void RHIPerFrameRHIFlushComplete();
|
||||
|
||||
// 执行命令队列, FlushType: Wait RHI Thread
|
||||
virtual void RHIExecuteCommandList(FRHICommandList* CmdList) = 0;
|
||||
|
||||
// FlushType: Flush RHI Thread
|
||||
virtual void* RHIGetNativeDevice() = 0;
|
||||
// FlushType: Flush RHI Thread
|
||||
virtual void* RHIGetNativeInstance() = 0;
|
||||
|
||||
// 获取命令上下文. FlushType: Thread safe
|
||||
virtual IRHICommandContext* RHIGetDefaultContext() = 0;
|
||||
// 获取计算上下文. FlushType: Thread safe
|
||||
virtual IRHIComputeContext* RHIGetDefaultAsyncComputeContext();
|
||||
|
||||
// FlushType: Thread safe
|
||||
virtual class IRHICommandContextContainer* RHIGetCommandContextContainer(int32 Index, int32 Num) = 0;
|
||||
|
||||
// 直接由渲染线程调用的接口, 以优化RHI调用.
|
||||
virtual FVertexBufferRHIRef CreateAndLockVertexBuffer_RenderThread(class FRHICommandListImmediate& RHICmdList, uint32 Size, uint32 InUsage, ERHIAccess InResourceState, FRHIResourceCreateInfo& CreateInfo, void*& OutDataBuffer);
|
||||
virtual FIndexBufferRHIRef CreateAndLockIndexBuffer_RenderThread(class FRHICommandListImmediate& RHICmdList, uint32 Stride, uint32 Size, uint32 InUsage, ERHIAccess InResourceState, FRHIResourceCreateInfo& CreateInfo, void*& OutDataBuffer);
|
||||
|
||||
(......)
|
||||
|
||||
// Buffer Lock/Unlock
|
||||
virtual void* LockVertexBuffer_BottomOfPipe(class FRHICommandListImmediate& RHICmdList, ...);
|
||||
virtual void* LockIndexBuffer_BottomOfPipe(class FRHICommandListImmediate& RHICmdList, ...);
|
||||
|
||||
(......)
|
||||
};
|
||||
```
|
||||
|
||||
以上只显示了部分接口,其中部分接口要求从渲染线程调用,部分须从游戏线程调用。大多数接口在被调用前需刷新指定类型的命令,比如:
|
||||
```c++
|
||||
class RHI_API FDynamicRHI
|
||||
{
|
||||
// FlushType: Wait RHI Thread
|
||||
void RHIExecuteCommandList(FRHICommandList* CmdList);
|
||||
|
||||
// FlushType: Flush Immediate
|
||||
void RHIBlockUntilGPUIdle();
|
||||
|
||||
// FlushType: Thread safe
|
||||
void RHITick(float DeltaTime);
|
||||
};
|
||||
```
|
||||
可以在**FRHICommandListImmediate**的**ExecuteCommandList()**、**BlockUntilGPUIdle()**、**Tick()** 看到调用。
|
||||
|
||||
>需要注意的是,传统图形API(D3D11、OpenGL)除了继承FDynamicRHI,还需要继承**IRHICommandContextPSOFallback**,因为需要借助后者的接口处理PSO的数据和行为,以保证传统和现代API对PSO的一致处理行为。也正因为此,现代图形API(D3D12、Vulkan、Metal)不需要继承**IRHICommandContext**的任何继承体系的类型,单单直接继承**FDynamicRHI**就可以处理RHI层的所有数据和操作。
|
||||
既然现代图形API(D3D12、Vulkan、Metal)的**DynamicRHI**没有继承**IRHICommandContext**的任何继承体系的类型,那么它们是如何实现FDynamicRHI::RHIGetDefaultContext的接口?下面以FD3D12DynamicRHI为例:
|
||||
|
||||
## FParallelCommandListSet
|
||||
```c++
|
||||
//Engine\Source\Runtime\Renderer\Private\DepthRendering.cpp
|
||||
void FDeferredShadingSceneRenderer::RenderPrePass(FRDGBuilder& GraphBuilder, FRDGTextureRef SceneDepthTexture, FInstanceCullingManager& InstanceCullingManager, FRDGTextureRef* FirstStageDepthBuffer)
|
||||
{
|
||||
RDG_EVENT_SCOPE(GraphBuilder, "PrePass %s %s", GetDepthDrawingModeString(DepthPass.EarlyZPassMode), GetDepthPassReason(DepthPass.bDitheredLODTransitionsUseStencil, ShaderPlatform));
|
||||
RDG_CSV_STAT_EXCLUSIVE_SCOPE(GraphBuilder, RenderPrePass);
|
||||
RDG_GPU_STAT_SCOPE(GraphBuilder, Prepass);
|
||||
|
||||
SCOPED_NAMED_EVENT(FDeferredShadingSceneRenderer_RenderPrePass, FColor::Emerald);
|
||||
SCOPE_CYCLE_COUNTER(STAT_DepthDrawTime);
|
||||
|
||||
const bool bParallelDepthPass = GRHICommandList.UseParallelAlgorithms() && CVarParallelPrePass.GetValueOnRenderThread();
|
||||
|
||||
RenderPrePassHMD(GraphBuilder, SceneDepthTexture);
|
||||
|
||||
if (DepthPass.IsRasterStencilDitherEnabled())
|
||||
{
|
||||
AddDitheredStencilFillPass(GraphBuilder, Views, SceneDepthTexture, DepthPass);
|
||||
}
|
||||
|
||||
auto RenderDepthPass = [&](uint8 DepthMeshPass)
|
||||
{
|
||||
check(DepthMeshPass == EMeshPass::DepthPass || DepthMeshPass == EMeshPass::SecondStageDepthPass);
|
||||
const bool bSecondStageDepthPass = DepthMeshPass == EMeshPass::SecondStageDepthPass;
|
||||
|
||||
if (bParallelDepthPass)
|
||||
{
|
||||
RDG_WAIT_FOR_TASKS_CONDITIONAL(GraphBuilder, IsDepthPassWaitForTasksEnabled());
|
||||
|
||||
for (int32 ViewIndex = 0; ViewIndex < Views.Num(); ++ViewIndex)
|
||||
{
|
||||
FViewInfo& View = Views[ViewIndex];
|
||||
RDG_GPU_MASK_SCOPE(GraphBuilder, View.GPUMask);
|
||||
RDG_EVENT_SCOPE_CONDITIONAL(GraphBuilder, Views.Num() > 1, "View%d", ViewIndex);
|
||||
|
||||
FMeshPassProcessorRenderState DrawRenderState;
|
||||
SetupDepthPassState(DrawRenderState);
|
||||
|
||||
const bool bShouldRenderView = View.ShouldRenderView() && (bSecondStageDepthPass ? View.bUsesSecondStageDepthPass : true);
|
||||
if (bShouldRenderView)
|
||||
{
|
||||
View.BeginRenderView();
|
||||
|
||||
FDepthPassParameters* PassParameters = GetDepthPassParameters(GraphBuilder, View, SceneDepthTexture);
|
||||
View.ParallelMeshDrawCommandPasses[DepthMeshPass].BuildRenderingCommands(GraphBuilder, Scene->GPUScene, PassParameters->InstanceCullingDrawParams);
|
||||
|
||||
GraphBuilder.AddPass(
|
||||
bSecondStageDepthPass ? RDG_EVENT_NAME("SecondStageDepthPassParallel") : RDG_EVENT_NAME("DepthPassParallel"),
|
||||
PassParameters,
|
||||
ERDGPassFlags::Raster | ERDGPassFlags::SkipRenderPass,
|
||||
[this, &View, PassParameters, DepthMeshPass](const FRDGPass* InPass, FRHICommandListImmediate& RHICmdList)
|
||||
{
|
||||
//并行渲染逻辑主要在这里
|
||||
FRDGParallelCommandListSet ParallelCommandListSet(InPass, RHICmdList, GET_STATID(STAT_CLP_Prepass), View, FParallelCommandListBindings(PassParameters));
|
||||
ParallelCommandListSet.SetHighPriority();
|
||||
View.ParallelMeshDrawCommandPasses[DepthMeshPass].DispatchDraw(&ParallelCommandListSet, RHICmdList, &PassParameters->InstanceCullingDrawParams);
|
||||
});
|
||||
|
||||
RenderPrePassEditorPrimitives(GraphBuilder, View, PassParameters, DrawRenderState, DepthPass.EarlyZPassMode, InstanceCullingManager);
|
||||
}
|
||||
}
|
||||
}
|
||||
···
|
||||
}
|
||||
|
||||
//Engine\Source\Runtime\Renderer\Private\MeshDrawCommands.cpp
|
||||
void FParallelMeshDrawCommandPass::DispatchDraw(FParallelCommandListSet* ParallelCommandListSet, FRHICommandList& RHICmdList, const FInstanceCullingDrawParams* InstanceCullingDrawParams) const
|
||||
{
|
||||
TRACE_CPUPROFILER_EVENT_SCOPE(ParallelMdcDispatchDraw);
|
||||
if (MaxNumDraws <= 0)
|
||||
{
|
||||
return;
|
||||
}
|
||||
|
||||
FMeshDrawCommandOverrideArgs OverrideArgs;
|
||||
if (InstanceCullingDrawParams)
|
||||
{
|
||||
OverrideArgs = GetMeshDrawCommandOverrideArgs(*InstanceCullingDrawParams);
|
||||
}
|
||||
|
||||
if (ParallelCommandListSet)
|
||||
{
|
||||
const ENamedThreads::Type RenderThread = ENamedThreads::GetRenderThread();
|
||||
|
||||
FGraphEventArray Prereqs;
|
||||
if (ParallelCommandListSet->GetPrereqs())
|
||||
{
|
||||
Prereqs.Append(*ParallelCommandListSet->GetPrereqs());
|
||||
}
|
||||
if (TaskEventRef.IsValid())
|
||||
{
|
||||
Prereqs.Add(TaskEventRef);
|
||||
}
|
||||
|
||||
// Distribute work evenly to the available task graph workers based on NumEstimatedDraws.
|
||||
// Every task will then adjust it's working range based on FVisibleMeshDrawCommandProcessTask results.
|
||||
const int32 NumThreads = FMath::Min<int32>(FTaskGraphInterface::Get().GetNumWorkerThreads(), ParallelCommandListSet->Width);
|
||||
const int32 NumTasks = FMath::Min<int32>(NumThreads, FMath::DivideAndRoundUp(MaxNumDraws, ParallelCommandListSet->MinDrawsPerCommandList));
|
||||
const int32 NumDrawsPerTask = FMath::DivideAndRoundUp(MaxNumDraws, NumTasks);
|
||||
|
||||
for (int32 TaskIndex = 0; TaskIndex < NumTasks; TaskIndex++)
|
||||
{
|
||||
const int32 StartIndex = TaskIndex * NumDrawsPerTask;
|
||||
const int32 NumDraws = FMath::Min(NumDrawsPerTask, MaxNumDraws - StartIndex);
|
||||
checkSlow(NumDraws > 0);
|
||||
|
||||
FRHICommandList* CmdList = ParallelCommandListSet->NewParallelCommandList();
|
||||
|
||||
FGraphEventRef AnyThreadCompletionEvent = TGraphTask<FDrawVisibleMeshCommandsAnyThreadTask>::CreateTask(&Prereqs, RenderThread)
|
||||
.ConstructAndDispatchWhenReady(*CmdList, TaskContext.InstanceCullingContext, TaskContext.MeshDrawCommands, TaskContext.MinimalPipelineStatePassSet,
|
||||
OverrideArgs,
|
||||
TaskContext.InstanceFactor,
|
||||
TaskIndex, NumTasks);
|
||||
|
||||
ParallelCommandListSet->AddParallelCommandList(CmdList, AnyThreadCompletionEvent, NumDraws);
|
||||
}
|
||||
}
|
||||
else
|
||||
{
|
||||
QUICK_SCOPE_CYCLE_COUNTER(STAT_MeshPassDrawImmediate);
|
||||
|
||||
WaitForMeshPassSetupTask(IsInActualRenderingThread() ? EWaitThread::Render : EWaitThread::Task);
|
||||
|
||||
if (TaskContext.bUseGPUScene)
|
||||
{
|
||||
if (TaskContext.MeshDrawCommands.Num() > 0)
|
||||
{
|
||||
TaskContext.InstanceCullingContext.SubmitDrawCommands(
|
||||
TaskContext.MeshDrawCommands,
|
||||
TaskContext.MinimalPipelineStatePassSet,
|
||||
OverrideArgs,
|
||||
0,
|
||||
TaskContext.MeshDrawCommands.Num(),
|
||||
TaskContext.InstanceFactor,
|
||||
RHICmdList);
|
||||
}
|
||||
}
|
||||
else
|
||||
{
|
||||
SubmitMeshDrawCommandsRange(TaskContext.MeshDrawCommands, TaskContext.MinimalPipelineStatePassSet, nullptr, 0, 0, TaskContext.bDynamicInstancing, 0, TaskContext.MeshDrawCommands.Num(), TaskContext.InstanceFactor, RHICmdList);
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## 普通Pass渲染
|
||||
```c++
|
||||
// 代码为UE5旧版本代码
|
||||
// Engine\Source\Runtime\RHI\Public\RHIResources.h
|
||||
|
||||
// 渲染通道信息.
|
||||
struct FRHIRenderPassInfo
|
||||
{
|
||||
// 渲染纹理信息.
|
||||
struct FColorEntry
|
||||
{
|
||||
FRHITexture* RenderTarget;
|
||||
FRHITexture* ResolveTarget;
|
||||
int32 ArraySlice;
|
||||
uint8 MipIndex;
|
||||
ERenderTargetActions Action;
|
||||
};
|
||||
FColorEntry ColorRenderTargets[MaxSimultaneousRenderTargets];
|
||||
|
||||
// 深度模板信息.
|
||||
struct FDepthStencilEntry
|
||||
{
|
||||
FRHITexture* DepthStencilTarget;
|
||||
FRHITexture* ResolveTarget;
|
||||
EDepthStencilTargetActions Action;
|
||||
FExclusiveDepthStencil ExclusiveDepthStencil;
|
||||
};
|
||||
FDepthStencilEntry DepthStencilRenderTarget;
|
||||
|
||||
// 解析参数.
|
||||
FResolveParams ResolveParameters;
|
||||
|
||||
// 部分RHI可以使用纹理来控制不同区域的采样和/或阴影分辨率
|
||||
FTextureRHIRef FoveationTexture = nullptr;
|
||||
|
||||
// 部分RHI需要一个提示,遮挡查询将在这个渲染通道中使用
|
||||
uint32 NumOcclusionQueries = 0;
|
||||
bool bOcclusionQueries = false;
|
||||
|
||||
// 部分RHI需要知道,在为部分资源转换生成mip映射的情况下,这个渲染通道是否将读取和写入相同的纹理.
|
||||
bool bGeneratingMips = false;
|
||||
|
||||
// 如果这个renderpass应该是多视图,则需要多少视图.
|
||||
uint8 MultiViewCount = 0;
|
||||
|
||||
// 部分RHI的提示,渲染通道将有特定的子通道.
|
||||
ESubpassHint SubpassHint = ESubpassHint::None;
|
||||
|
||||
// 是否太多UAV.
|
||||
bool bTooManyUAVs = false;
|
||||
bool bIsMSAA = false;
|
||||
|
||||
// 不同的构造函数.
|
||||
|
||||
// Color, no depth, optional resolve, optional mip, optional array slice
|
||||
explicit FRHIRenderPassInfo(FRHITexture* ColorRT, ERenderTargetActions ColorAction, FRHITexture* ResolveRT = nullptr, uint32 InMipIndex = 0, int32 InArraySlice = -1);
|
||||
// Color MRTs, no depth
|
||||
explicit FRHIRenderPassInfo(int32 NumColorRTs, FRHITexture* ColorRTs[], ERenderTargetActions ColorAction);
|
||||
// Color MRTs, no depth
|
||||
explicit FRHIRenderPassInfo(int32 NumColorRTs, FRHITexture* ColorRTs[], ERenderTargetActions ColorAction, FRHITexture* ResolveTargets[]);
|
||||
// Color MRTs and depth
|
||||
explicit FRHIRenderPassInfo(int32 NumColorRTs, FRHITexture* ColorRTs[], ERenderTargetActions ColorAction, FRHITexture* DepthRT, EDepthStencilTargetActions DepthActions, FExclusiveDepthStencil InEDS = FExclusiveDepthStencil::DepthWrite_StencilWrite);
|
||||
// Color MRTs and depth
|
||||
explicit FRHIRenderPassInfo(int32 NumColorRTs, FRHITexture* ColorRTs[], ERenderTargetActions ColorAction, FRHITexture* ResolveRTs[], FRHITexture* DepthRT, EDepthStencilTargetActions DepthActions, FRHITexture* ResolveDepthRT, FExclusiveDepthStencil InEDS = FExclusiveDepthStencil::DepthWrite_StencilWrite);
|
||||
// Depth, no color
|
||||
explicit FRHIRenderPassInfo(FRHITexture* DepthRT, EDepthStencilTargetActions DepthActions, FRHITexture* ResolveDepthRT = nullptr, FExclusiveDepthStencil InEDS = FExclusiveDepthStencil::DepthWrite_StencilWrite);
|
||||
// Depth, no color, occlusion queries
|
||||
explicit FRHIRenderPassInfo(FRHITexture* DepthRT, uint32 InNumOcclusionQueries, EDepthStencilTargetActions DepthActions, FRHITexture* ResolveDepthRT = nullptr, FExclusiveDepthStencil InEDS = FExclusiveDepthStencil::DepthWrite_StencilWrite);
|
||||
// Color and depth
|
||||
explicit FRHIRenderPassInfo(FRHITexture* ColorRT, ERenderTargetActions ColorAction, FRHITexture* DepthRT, EDepthStencilTargetActions DepthActions, FExclusiveDepthStencil InEDS = FExclusiveDepthStencil::DepthWrite_StencilWrite);
|
||||
// Color and depth with resolve
|
||||
explicit FRHIRenderPassInfo(FRHITexture* ColorRT, ERenderTargetActions ColorAction, FRHITexture* ResolveColorRT,
|
||||
FRHITexture* DepthRT, EDepthStencilTargetActions DepthActions, FRHITexture* ResolveDepthRT, FExclusiveDepthStencil InEDS = FExclusiveDepthStencil::DepthWrite_StencilWrite);
|
||||
// Color and depth with resolve and optional sample density
|
||||
explicit FRHIRenderPassInfo(FRHITexture* ColorRT, ERenderTargetActions ColorAction, FRHITexture* ResolveColorRT,
|
||||
FRHITexture* DepthRT, EDepthStencilTargetActions DepthActions, FRHITexture* ResolveDepthRT, FRHITexture* InFoveationTexture, FExclusiveDepthStencil InEDS = FExclusiveDepthStencil::DepthWrite_StencilWrite);
|
||||
|
||||
enum ENoRenderTargets
|
||||
{
|
||||
NoRenderTargets,
|
||||
};
|
||||
explicit FRHIRenderPassInfo(ENoRenderTargets Dummy);
|
||||
explicit FRHIRenderPassInfo();
|
||||
|
||||
inline int32 GetNumColorRenderTargets() const;
|
||||
RHI_API void Validate() const;
|
||||
RHI_API void ConvertToRenderTargetsInfo(FRHISetRenderTargetsInfo& OutRTInfo) const;
|
||||
|
||||
(......)
|
||||
};
|
||||
|
||||
// Engine\Source\Runtime\RHI\Public\RHICommandList.h
|
||||
|
||||
class RHI_API FRHICommandList : public FRHIComputeCommandList
|
||||
{
|
||||
public:
|
||||
void BeginRenderPass(const FRHIRenderPassInfo& InInfo, const TCHAR* Name)
|
||||
{
|
||||
if (InInfo.bTooManyUAVs)
|
||||
{
|
||||
UE_LOG(LogRHI, Warning, TEXT("RenderPass %s has too many UAVs"));
|
||||
}
|
||||
InInfo.Validate();
|
||||
|
||||
// 直接调用RHI的接口.
|
||||
if (Bypass())
|
||||
{
|
||||
GetContext().RHIBeginRenderPass(InInfo, Name);
|
||||
}
|
||||
// 分配RHI命令.
|
||||
else
|
||||
{
|
||||
TCHAR* NameCopy = AllocString(Name);
|
||||
ALLOC_COMMAND(FRHICommandBeginRenderPass)(InInfo, NameCopy);
|
||||
}
|
||||
// 设置在RenderPass内标记.
|
||||
Data.bInsideRenderPass = true;
|
||||
|
||||
// 缓存活动的RT.
|
||||
CacheActiveRenderTargets(InInfo);
|
||||
// 重置子Pass.
|
||||
ResetSubpass(InInfo.SubpassHint);
|
||||
Data.bInsideRenderPass = true;
|
||||
}
|
||||
|
||||
void EndRenderPass()
|
||||
{
|
||||
// 调用或分配RHI接口.
|
||||
if (Bypass())
|
||||
{
|
||||
GetContext().RHIEndRenderPass();
|
||||
}
|
||||
else
|
||||
{
|
||||
ALLOC_COMMAND(FRHICommandEndRenderPass)();
|
||||
}
|
||||
// 重置在RenderPass内标记.
|
||||
Data.bInsideRenderPass = false;
|
||||
// 重置子Pass标记为None.
|
||||
ResetSubpass(ESubpassHint::None);
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
它们的使用案例如下:
|
||||
主要是`FRHIRenderPassInfo RenderPassInfo(1, ColorRTs, ERenderTargetActions::DontLoad_DontStore)`与`RHICmdList.BeginRenderPass(RenderPassInfo, TEXT("Test_MultiDrawIndirect"))`
|
||||
```c++
|
||||
bool FRHIDrawTests::Test_MultiDrawIndirect(FRHICommandListImmediate& RHICmdList)
|
||||
{
|
||||
if (!GRHIGlobals.SupportsMultiDrawIndirect)
|
||||
{
|
||||
return true;
|
||||
}
|
||||
|
||||
// Probably could/should automatically enable in the outer scope when running RHI Unit Tests
|
||||
// RenderCaptureInterface::FScopedCapture RenderCapture(true /*bEnable*/, &RHICmdList, TEXT("Test_MultiDrawIndirect"));
|
||||
|
||||
static constexpr uint32 MaxInstances = 8;
|
||||
|
||||
// D3D12 does not have a way to get the base instance ID (SV_InstanceID always starts from 0), so we must emulate it...
|
||||
const uint32 InstanceIDs[MaxInstances] = { 0, 1, 2, 3, 4, 5, 6, 7 };
|
||||
FBufferRHIRef InstanceIDBuffer = CreateBufferWithData(EBufferUsageFlags::VertexBuffer, ERHIAccess::VertexOrIndexBuffer, TEXT("Test_MultiDrawIndirect_InstanceID"), MakeArrayView(InstanceIDs));
|
||||
|
||||
FVertexDeclarationElementList VertexDeclarationElements;
|
||||
VertexDeclarationElements.Add(FVertexElement(0, 0, VET_UInt, 0, 4, true /*per instance frequency*/));
|
||||
FVertexDeclarationRHIRef VertexDeclarationRHI = PipelineStateCache::GetOrCreateVertexDeclaration(VertexDeclarationElements);
|
||||
|
||||
const uint16 Indices[3] = { 0, 1, 2 };
|
||||
FBufferRHIRef IndexBuffer = CreateBufferWithData(EBufferUsageFlags::IndexBuffer, ERHIAccess::VertexOrIndexBuffer, TEXT("Test_MultiDrawIndirect_IndexBuffer"), MakeArrayView(Indices));
|
||||
|
||||
static constexpr uint32 OutputBufferStride = sizeof(uint32);
|
||||
static constexpr uint32 OutputBufferSize = OutputBufferStride * MaxInstances;
|
||||
FRHIResourceCreateInfo OutputBufferCreateInfo(TEXT("Test_MultiDrawIndirect_OutputBuffer"));
|
||||
FBufferRHIRef OutputBuffer = RHICmdList.CreateBuffer(OutputBufferSize, EBufferUsageFlags::UnorderedAccess | EBufferUsageFlags::SourceCopy, OutputBufferStride, ERHIAccess::UAVCompute, OutputBufferCreateInfo);
|
||||
|
||||
const uint32 CountValues[4] = { 1, 1, 16, 0 };
|
||||
FBufferRHIRef CountBuffer = CreateBufferWithData(EBufferUsageFlags::DrawIndirect | EBufferUsageFlags::UnorderedAccess, ERHIAccess::IndirectArgs, TEXT("Test_MultiDrawIndirect_Count"), MakeArrayView(CountValues));
|
||||
|
||||
const FRHIDrawIndexedIndirectParameters DrawArgs[] =
|
||||
{
|
||||
// IndexCountPerInstance, InstanceCount, StartIndexLocation, BaseVertexLocation, StartInstanceLocation
|
||||
{3, 1, 0, 0, 0}, // fill slot 0
|
||||
// gap in slot 1
|
||||
{3, 2, 0, 0, 2}, // fill slots 2, 3 using 1 sub-draw
|
||||
// gap in slot 4
|
||||
{3, 1, 0, 0, 5}, // fill slots 5, 6 using 2 sub-draws
|
||||
{3, 1, 0, 0, 6},
|
||||
{3, 1, 0, 0, 7}, // this draw is expected to never execute
|
||||
};
|
||||
|
||||
const uint32 ExpectedDrawnInstances[MaxInstances] = { 1, 0, 1, 1, 0, 1, 1, 0 };
|
||||
|
||||
FBufferRHIRef DrawArgBuffer = CreateBufferWithData(EBufferUsageFlags::DrawIndirect | EBufferUsageFlags::UnorderedAccess | EBufferUsageFlags::VertexBuffer, ERHIAccess::IndirectArgs,
|
||||
TEXT("Test_MultiDrawIndirect_DrawArgs"), MakeArrayView(DrawArgs));
|
||||
|
||||
FUnorderedAccessViewRHIRef OutputBufferUAV = RHICmdList.CreateUnorderedAccessView(OutputBuffer,
|
||||
FRHIViewDesc::CreateBufferUAV()
|
||||
.SetType(FRHIViewDesc::EBufferType::Typed)
|
||||
.SetFormat(PF_R32_UINT));
|
||||
|
||||
RHICmdList.ClearUAVUint(OutputBufferUAV, FUintVector4(0));
|
||||
|
||||
const FIntPoint RenderTargetSize(4, 4);
|
||||
FRHITextureDesc RenderTargetTextureDesc(ETextureDimension::Texture2D, ETextureCreateFlags::RenderTargetable, PF_B8G8R8A8, FClearValueBinding(), RenderTargetSize, 1, 1, 1, 1, 0);
|
||||
FRHITextureCreateDesc RenderTargetCreateDesc(RenderTargetTextureDesc, ERHIAccess::RTV, TEXT("Test_MultiDrawIndirect_RenderTarget"));
|
||||
FTextureRHIRef RenderTarget = RHICreateTexture(RenderTargetCreateDesc);
|
||||
|
||||
TShaderMapRef<FTestDrawInstancedVS> VertexShader(GetGlobalShaderMap(GMaxRHIFeatureLevel));
|
||||
TShaderMapRef<FTestDrawInstancedPS> PixelShader(GetGlobalShaderMap(GMaxRHIFeatureLevel));
|
||||
|
||||
FGraphicsPipelineStateInitializer GraphicsPSOInit;
|
||||
|
||||
GraphicsPSOInit.BoundShaderState.VertexShaderRHI = VertexShader.GetVertexShader();
|
||||
GraphicsPSOInit.BoundShaderState.VertexDeclarationRHI = VertexDeclarationRHI;
|
||||
GraphicsPSOInit.BoundShaderState.PixelShaderRHI = PixelShader.GetPixelShader();
|
||||
GraphicsPSOInit.DepthStencilState = TStaticDepthStencilState<false, CF_Always>::GetRHI();
|
||||
GraphicsPSOInit.BlendState = TStaticBlendState<>::GetRHI();
|
||||
GraphicsPSOInit.RasterizerState = TStaticRasterizerState<>::GetRHI();
|
||||
GraphicsPSOInit.PrimitiveType = EPrimitiveType::PT_TriangleList;
|
||||
|
||||
FRHITexture* ColorRTs[1] = { RenderTarget.GetReference() };
|
||||
FRHIRenderPassInfo RenderPassInfo(1, ColorRTs, ERenderTargetActions::DontLoad_DontStore);
|
||||
|
||||
RHICmdList.Transition(FRHITransitionInfo(OutputBufferUAV, ERHIAccess::UAVCompute, ERHIAccess::UAVGraphics, EResourceTransitionFlags::None));
|
||||
RHICmdList.BeginUAVOverlap(); // Output UAV can be written without syncs between draws (each draw is expected to write into different slots)
|
||||
|
||||
RHICmdList.BeginRenderPass(RenderPassInfo, TEXT("Test_MultiDrawIndirect"));
|
||||
RHICmdList.SetViewport(0, 0, 0, float(RenderTargetSize.X), float(RenderTargetSize.Y), 1);
|
||||
|
||||
RHICmdList.ApplyCachedRenderTargets(GraphicsPSOInit);
|
||||
SetGraphicsPipelineState(RHICmdList, GraphicsPSOInit, 0);
|
||||
|
||||
check(InstanceIDBuffer->GetStride() == 4);
|
||||
RHICmdList.SetStreamSource(0, InstanceIDBuffer, 0);
|
||||
|
||||
FRHIBatchedShaderParameters ShaderParameters;
|
||||
ShaderParameters.SetUAVParameter(PixelShader->OutDrawnInstances.GetBaseIndex(), OutputBufferUAV);
|
||||
RHICmdList.SetBatchedShaderParameters(PixelShader.GetPixelShader(), ShaderParameters);
|
||||
|
||||
const uint32 DrawArgsStride = sizeof(DrawArgs[0]);
|
||||
const uint32 CountStride = sizeof(CountValues[0]);
|
||||
|
||||
RHICmdList.MultiDrawIndexedPrimitiveIndirect(IndexBuffer,
|
||||
DrawArgBuffer, DrawArgsStride*0, // 1 sub-draw with instance index 0
|
||||
CountBuffer, CountStride*0, // count buffer contains 1 in this slot
|
||||
5 // expect to draw only 1 instance due to GPU-side upper bound
|
||||
);
|
||||
|
||||
RHICmdList.MultiDrawIndexedPrimitiveIndirect(IndexBuffer,
|
||||
DrawArgBuffer, DrawArgsStride*1, // 1 sub-draw with 2 instances at base index 2
|
||||
CountBuffer, CountStride*1, // count buffer contains 1 in this slot
|
||||
4 // expect to draw only 1 instance due to GPU-side upper bound
|
||||
);
|
||||
|
||||
RHICmdList.MultiDrawIndexedPrimitiveIndirect(IndexBuffer,
|
||||
DrawArgBuffer, DrawArgsStride*2, // 2 sub-draws with 1 instance each starting at base index 5
|
||||
CountBuffer, CountStride*2, // count buffer contains 16 in this slot
|
||||
2 // expect to draw only 2 instances due to CPU-side upper bound
|
||||
);
|
||||
|
||||
RHICmdList.MultiDrawIndexedPrimitiveIndirect(IndexBuffer,
|
||||
DrawArgBuffer, DrawArgsStride*4, // 1 sub-draw with 1 instance each starting at base index 7
|
||||
CountBuffer, CountStride*3, // count buffer contains 0 in this slot
|
||||
1 // expect to skip the draw due to GPU-side count of 0
|
||||
);
|
||||
|
||||
RHICmdList.MultiDrawIndexedPrimitiveIndirect(IndexBuffer,
|
||||
DrawArgBuffer, DrawArgsStride*4, // 1 sub-draw with 1 instance each starting at base index 7
|
||||
CountBuffer, CountStride*0, // count buffer contains 1 in this slot
|
||||
0 // expect to skip the draw due to CPU-side count of 0
|
||||
);
|
||||
|
||||
RHICmdList.EndRenderPass();
|
||||
|
||||
RHICmdList.EndUAVOverlap();
|
||||
|
||||
RHICmdList.Transition(FRHITransitionInfo(OutputBufferUAV, ERHIAccess::UAVGraphics, ERHIAccess::CopySrc, EResourceTransitionFlags::None));
|
||||
|
||||
TConstArrayView<uint8> ExpectedOutputView = MakeArrayView(reinterpret_cast<const uint8*>(ExpectedDrawnInstances), sizeof(ExpectedDrawnInstances));
|
||||
bool bSucceeded = FRHIBufferTests::VerifyBufferContents(TEXT("Test_MultiDrawIndirect"), RHICmdList, OutputBuffer, ExpectedOutputView);
|
||||
|
||||
return bSucceeded;
|
||||
}
|
||||
```
|
||||
|
||||
## Subpass
|
||||
先说一下Subpass的由来、作用和特点。
|
||||
|
||||
在传统的多Pass渲染中,每个Pass结束时通常会渲染出一组渲染纹理,部分成为着色器参数提供给下一个Pass采样读取。这种纹理采样方式不受任何限制,可以读取任意的领域像素,使用任意的纹理过滤方式。这种方式虽然使用灵活,但在TBR(Tile-Based Renderer)硬件架构的设备中会有较大的消耗:渲染纹理的Pass通常会将渲染结果存储在On-chip的Tile Memory中,待Pass结束后会写回GPU显存(VRAM)中,写回GPU显存是个耗时耗耗电的操作。
|
||||
|
||||
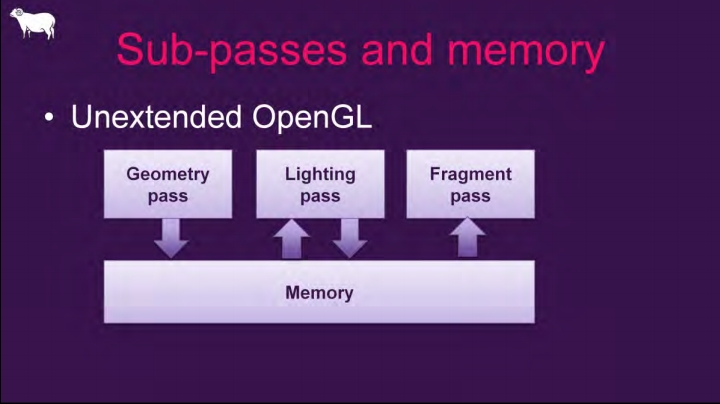
|
||||
|
||||
_传统多Pass之间的内存存取模型,多次发生于On-Chip和全局存储器之间。_
|
||||
|
||||
如果出现一种特殊的纹理使用情况:上一个Pass渲染处理的纹理,立即被下一个Pass使用,并且下一个Pass只采样像素位置自身的数据,而不需要采样邻域像素的位置。这种情况就符合了Subpass的使用情景。使用Subpass渲染的纹理结果只会存储在Tile Memory中,在Subpass结束后不会写回VRAM,而直接提供Tile Memory的数据给下一个Subpass采样读取。这样就避免了传统Pass结束写回GPU显存以及下一个Pass又从GPU显存读数据的耗时耗电操作,从而提升了性能。
|
||||
|
||||
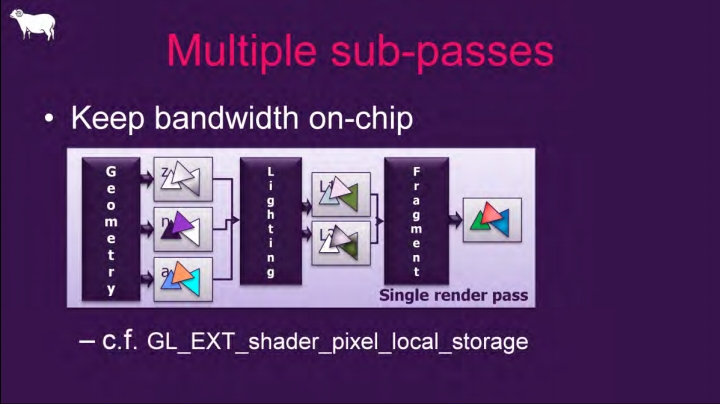
|
||||
|
||||
_Subpass之间的内存存取模型,都发生在On-Chip内。_
|
||||
|
||||
Subpass的相关代码主要集中在移动端中。UE涉及Subpass的接口和类型如下:
|
||||
```c++
|
||||
// 提供给RHI的Subpass标记.
|
||||
enum class ESubpassHint : uint8
|
||||
{
|
||||
None, // 传统渲染(非Subpass)
|
||||
DepthReadSubpass, // 深度读取Subpass.
|
||||
DeferredShadingSubpass, // 移动端延迟着色Subpass.
|
||||
};
|
||||
|
||||
|
||||
// Engine\Source\Runtime\RHI\Public\RHICommandList.h
|
||||
|
||||
class RHI_API FRHICommandListBase : public FNoncopyable
|
||||
{
|
||||
(......)
|
||||
|
||||
protected:
|
||||
// PSO上下文.
|
||||
struct FPSOContext
|
||||
{
|
||||
uint32 CachedNumSimultanousRenderTargets = 0;
|
||||
TStaticArray<FRHIRenderTargetView, MaxSimultaneousRenderTargets> CachedRenderTargets;
|
||||
FRHIDepthRenderTargetView CachedDepthStencilTarget;
|
||||
|
||||
// Subpass提示标记.
|
||||
ESubpassHint SubpassHint = ESubpassHint::None;
|
||||
uint8 SubpassIndex = 0;
|
||||
uint8 MultiViewCount = 0;
|
||||
bool HasFragmentDensityAttachment = false;
|
||||
} PSOContext;
|
||||
};
|
||||
|
||||
class RHI_API FRHICommandList : public FRHIComputeCommandList
|
||||
{
|
||||
public:
|
||||
void BeginRenderPass(const FRHIRenderPassInfo& InInfo, const TCHAR* Name)
|
||||
{
|
||||
(......)
|
||||
|
||||
CacheActiveRenderTargets(InInfo);
|
||||
// 设置Subpass数据.
|
||||
ResetSubpass(InInfo.SubpassHint);
|
||||
Data.bInsideRenderPass = true;
|
||||
}
|
||||
|
||||
void EndRenderPass()
|
||||
{
|
||||
(......)
|
||||
|
||||
// 重置Subpass标记为None.
|
||||
ResetSubpass(ESubpassHint::None);
|
||||
}
|
||||
|
||||
// 下一个Subpass.
|
||||
void NextSubpass()
|
||||
{
|
||||
// 分配或调用RHI接口.
|
||||
if (Bypass())
|
||||
{
|
||||
GetContext().RHINextSubpass();
|
||||
}
|
||||
else
|
||||
{
|
||||
ALLOC_COMMAND(FRHICommandNextSubpass)();
|
||||
}
|
||||
|
||||
// 增加Subpass计数.
|
||||
IncrementSubpass();
|
||||
}
|
||||
|
||||
// 增加subpass计数.
|
||||
void IncrementSubpass()
|
||||
{
|
||||
PSOContext.SubpassIndex++;
|
||||
}
|
||||
|
||||
// 重置Subpass数据.
|
||||
void ResetSubpass(ESubpassHint SubpassHint)
|
||||
{
|
||||
PSOContext.SubpassHint = SubpassHint;
|
||||
PSOContext.SubpassIndex = 0;
|
||||
}
|
||||
};
|
||||
```
|
||||
@@ -0,0 +1,365 @@
|
||||
---
|
||||
title: 剖析虚幻渲染体系(11)- RDG
|
||||
date: 2024-02-04 21:42:54
|
||||
excerpt:
|
||||
tags:
|
||||
rating: ⭐
|
||||
---
|
||||
# 前言
|
||||
原文地址:https://www.cnblogs.com/timlly/p/15217090.html
|
||||
|
||||
# 概念
|
||||
- FRDGAllocator:简单的C++对象分配器, 用MemStack分配器追踪和销毁物体。
|
||||
- FComputeShaderUtils
|
||||
- Dispatch():派发ComputeShader到RHI命令列表,携带其参数。
|
||||
- DispatchIndirect():派发非直接的ComputeShader到RHI命令列表,,携带其参数。
|
||||
- AddPass():派发计算着色器到**RenderGraphBuilder**, 携带其参数。
|
||||
- ClearUAV():清理UAV。
|
||||
- AddCopyTexturePass():增加拷贝纹理Pass。
|
||||
- AddCopyToResolveTargetPass():增加拷贝到解析目标的Pass。
|
||||
- AddEnqueueCopyPass():增加回读纹理的Pass。
|
||||
- AddPass():无参数的Pass增加。
|
||||
- AddBeginUAVOverlapPass()/AddEndUAVOverlapPass(): 其它特殊Pass。
|
||||
- FRDGResource:RDG资源并不是直接用RHI资源,而是包裹了RHI资源引用,然后针对不同类型的资源各自封装,且增加了额外的信息。
|
||||
- FRDGUniformBuffer、TRDGUniformBuffer
|
||||
- FRDGParentResource:一种由图跟踪分配生命周期的渲染图资源。可能有引用它的子资源(例如视图)
|
||||
- FRDGView
|
||||
- FRDGBuffer、FRDGBufferSRV、FRDGBufferUAV
|
||||
- FRDGViewableResource:一种由图跟踪分配生命周期的RPGResource。可能有引用它的子资源
|
||||
- FRDGTexture
|
||||
- FRDGView
|
||||
- FRDGUnorderedAccessView、FRDGTextureUAV
|
||||
- FRDGShaderResourceView、FRDGTextureSRV
|
||||
- FRDGTextureDesc:创建渲染纹理的描述信息。
|
||||
- FRDGPooledTexture:贴图池里的贴图资源。
|
||||
- FRDGPooledBuffer:池化的缓冲区。
|
||||
- FRHITransition:用于表示RHI中挂起的资源转换的**不透明表面材质**数据结构。
|
||||
- FRDGBarrierBatch:RDG屏障批。
|
||||
- FRDGBarrierBatchBegin
|
||||
- FRDGBarrierBatchEnd
|
||||
- FRDGPass
|
||||
- TRDGLambdaPass
|
||||
- FRDGSentinelPass:哨兵Pass,用于开始/结束。
|
||||
- [[#FRDGBuilder]]
|
||||
|
||||
## RDG基础类型
|
||||
```c++
|
||||
enum class ERDGBuilderFlags
|
||||
{
|
||||
None = 0,
|
||||
|
||||
/** Allows the builder to parallelize execution of passes. Without this flag, all passes execute on the render thread. */
|
||||
AllowParallelExecute = 1 << 0
|
||||
};
|
||||
|
||||
/** Flags to annotate a pass with when calling AddPass. */
|
||||
enum class ERDGPassFlags : uint16
|
||||
{
|
||||
/** Pass doesn't have any inputs or outputs tracked by the graph. This may only be used by the parameterless AddPass function. */
|
||||
None = 0,
|
||||
|
||||
/** Pass uses rasterization on the graphics pipe. */
|
||||
Raster = 1 << 0,
|
||||
|
||||
/** Pass uses compute on the graphics pipe. */
|
||||
Compute = 1 << 1,
|
||||
|
||||
/** Pass uses compute on the async compute pipe. */
|
||||
AsyncCompute = 1 << 2,
|
||||
|
||||
/** Pass uses copy commands on the graphics pipe. */
|
||||
Copy = 1 << 3,
|
||||
|
||||
/** Pass (and its producers) will never be culled. Necessary if outputs cannot be tracked by the graph. */
|
||||
NeverCull = 1 << 4,
|
||||
|
||||
/** Render pass begin / end is skipped and left to the user. Only valid when combined with 'Raster'. Disables render pass merging for the pass. */
|
||||
SkipRenderPass = 1 << 5,
|
||||
|
||||
/** Pass will never have its render pass merged with other passes. */
|
||||
NeverMerge = 1 << 6,
|
||||
|
||||
/** Pass will never run off the render thread. */
|
||||
NeverParallel = 1 << 7,
|
||||
|
||||
ParallelTranslate = 1 << 8,
|
||||
|
||||
/** Pass uses copy commands but writes to a staging resource. */
|
||||
Readback = Copy | NeverCull
|
||||
};
|
||||
|
||||
/** Flags to annotate a render graph buffer. */
|
||||
enum class ERDGBufferFlags : uint8
|
||||
{
|
||||
None = 0,
|
||||
|
||||
/** Tag the buffer to survive through frame, that is important for multi GPU alternate frame rendering. */
|
||||
MultiFrame = 1 << 0,
|
||||
|
||||
/** The buffer is ignored by RDG tracking and will never be transitioned. Use the flag when registering a buffer with no writable GPU flags.
|
||||
* Write access is not allowed for the duration of the graph. This flag is intended as an optimization to cull out tracking of read-only
|
||||
* buffers that are used frequently throughout the graph. Note that it's the user's responsibility to ensure the resource is in the correct
|
||||
* readable state for use with RDG passes, as RDG does not know the exact state of the resource.
|
||||
*/
|
||||
SkipTracking = 1 << 1,
|
||||
|
||||
/** When set, RDG will perform its first barrier without splitting. Practically, this means the resource is left in its initial state
|
||||
* until the first pass it's used within the graph. Without this flag, the resource is split-transitioned at the start of the graph.
|
||||
*/
|
||||
ForceImmediateFirstBarrier = 1 << 2,
|
||||
};
|
||||
|
||||
/** Flags to annotate a render graph texture. */
|
||||
enum class ERDGTextureFlags : uint8
|
||||
{
|
||||
None = 0,
|
||||
|
||||
/** Tag the texture to survive through frame, that is important for multi GPU alternate frame rendering. */
|
||||
MultiFrame = 1 << 0,
|
||||
|
||||
/** The buffer is ignored by RDG tracking and will never be transitioned. Use the flag when registering a buffer with no writable GPU flags.
|
||||
* Write access is not allowed for the duration of the graph. This flag is intended as an optimization to cull out tracking of read-only
|
||||
* buffers that are used frequently throughout the graph. Note that it's the user's responsibility to ensure the resource is in the correct
|
||||
* readable state for use with RDG passes, as RDG does not know the exact state of the resource.
|
||||
*/
|
||||
SkipTracking = 1 << 1,
|
||||
|
||||
/** When set, RDG will perform its first barrier without splitting. Practically, this means the resource is left in its initial state
|
||||
* until the first pass it's used within the graph. Without this flag, the resource is split-transitioned at the start of the graph.
|
||||
*/
|
||||
ForceImmediateFirstBarrier = 1 << 2,
|
||||
|
||||
/** Prevents metadata decompression on this texture. */
|
||||
MaintainCompression = 1 << 3,
|
||||
};
|
||||
ENUM_CLASS_FLAGS(ERDGTextureFlags);
|
||||
|
||||
/** Flags to annotate a view with when calling CreateUAV. */
|
||||
enum class ERDGUnorderedAccessViewFlags : uint8
|
||||
{
|
||||
None = 0,
|
||||
|
||||
// The view will not perform UAV barriers between consecutive usage.
|
||||
SkipBarrier = 1 << 0
|
||||
};
|
||||
ENUM_CLASS_FLAGS(ERDGUnorderedAccessViewFlags);
|
||||
|
||||
/** The set of concrete parent resource types. */
|
||||
enum class ERDGViewableResourceType : uint8
|
||||
{
|
||||
Texture,
|
||||
Buffer,
|
||||
MAX
|
||||
};
|
||||
|
||||
/** The set of concrete view types. */
|
||||
enum class ERDGViewType : uint8
|
||||
{
|
||||
TextureUAV,
|
||||
TextureSRV,
|
||||
BufferUAV,
|
||||
BufferSRV,
|
||||
MAX
|
||||
};
|
||||
|
||||
inline ERDGViewableResourceType GetParentType(ERDGViewType ViewType)
|
||||
{
|
||||
switch (ViewType)
|
||||
{
|
||||
case ERDGViewType::TextureUAV:
|
||||
case ERDGViewType::TextureSRV:
|
||||
return ERDGViewableResourceType::Texture;
|
||||
case ERDGViewType::BufferUAV:
|
||||
case ERDGViewType::BufferSRV:
|
||||
return ERDGViewableResourceType::Buffer;
|
||||
}
|
||||
checkNoEntry();
|
||||
return ERDGViewableResourceType::MAX;
|
||||
}
|
||||
|
||||
enum class ERDGResourceExtractionFlags : uint8
|
||||
{
|
||||
None = 0,
|
||||
|
||||
// Allows the resource to remain transient. Only use this flag if you intend to register the resource back
|
||||
// into the graph and release the reference. This should not be used if the resource is cached for a long
|
||||
// period of time.
|
||||
AllowTransient = 1,
|
||||
};
|
||||
|
||||
enum class ERDGInitialDataFlags : uint8
|
||||
{
|
||||
/** Specifies the default behavior, which is to make a copy of the initial data for replay when
|
||||
* the graph is executed. The user does not need to preserve lifetime of the data pointer.
|
||||
*/
|
||||
None = 0,
|
||||
|
||||
/** Specifies that the user will maintain ownership of the data until the graph is executed. The
|
||||
* upload pass will only use a reference to store the data. Use caution with this flag since graph
|
||||
* execution is deferred! Useful to avoid the copy if the initial data lifetime is guaranteed to
|
||||
* outlive the graph.
|
||||
*/
|
||||
NoCopy = 1 << 0
|
||||
};
|
||||
|
||||
enum class ERDGPooledBufferAlignment : uint8
|
||||
{
|
||||
// The buffer size is not aligned.
|
||||
None,
|
||||
|
||||
// The buffer size is aligned up to the next page size.
|
||||
Page,
|
||||
|
||||
// The buffer size is aligned up to the next power of two.
|
||||
PowerOfTwo
|
||||
};
|
||||
|
||||
/** Returns the equivalent parent resource type for a view type. */
|
||||
inline ERDGViewableResourceType GetViewableResourceType(ERDGViewType ViewType)
|
||||
{
|
||||
switch (ViewType)
|
||||
{
|
||||
case ERDGViewType::TextureUAV:
|
||||
case ERDGViewType::TextureSRV:
|
||||
return ERDGViewableResourceType::Texture;
|
||||
case ERDGViewType::BufferUAV:
|
||||
case ERDGViewType::BufferSRV:
|
||||
return ERDGViewableResourceType::Buffer;
|
||||
default:
|
||||
checkNoEntry();
|
||||
return ERDGViewableResourceType::MAX;
|
||||
}
|
||||
}
|
||||
|
||||
using ERDGTextureMetaDataAccess = ERHITextureMetaDataAccess;
|
||||
|
||||
/** Returns the associated FRHITransitionInfo plane index. */
|
||||
inline int32 GetResourceTransitionPlaneForMetadataAccess(ERDGTextureMetaDataAccess Metadata)
|
||||
{
|
||||
switch (Metadata)
|
||||
{
|
||||
case ERDGTextureMetaDataAccess::CompressedSurface:
|
||||
case ERDGTextureMetaDataAccess::HTile:
|
||||
case ERDGTextureMetaDataAccess::Depth:
|
||||
return FRHITransitionInfo::kDepthPlaneSlice;
|
||||
case ERDGTextureMetaDataAccess::Stencil:
|
||||
return FRHITransitionInfo::kStencilPlaneSlice;
|
||||
default:
|
||||
return 0;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
## FRDGBuilder
|
||||
FRDGBuilder是RDG体系的心脏和发动机,也是个大管家,负责收集渲染Pass和参数,编译Pass、数据,处理资源依赖,裁剪和优化各类数据,还有提供执行接口。
|
||||
|
||||
重要函数:
|
||||
- FindExternalTexture():查找外部纹理, 若找不到返回null.
|
||||
- RegisterExternalTexture():注册外部池内RT到RDG, 以便RDG追踪之. 池内RT可能包含两种RHI纹理: MSAA和非MSAA。
|
||||
- RegisterExternalBuffer():注册外部缓冲区到RDG, 以便RDG追踪之.
|
||||
- 资源创建接口:
|
||||
- CreateTexture()
|
||||
- CreateBuffer()
|
||||
- CreateUAV()
|
||||
- CreateSRV()
|
||||
- CreateUniformBuffer()
|
||||
- 分配内存, 内存由RDG管理生命周期。
|
||||
- Alloc()
|
||||
- AllocPOD()
|
||||
- AllocObject()
|
||||
- AllocParameters()
|
||||
- AddPass()
|
||||
- FRDGPassRef AddPass(FRDGEventName&& Name, const ParameterStructType* ParameterStruct, ERDGPassFlags Flags, ExecuteLambdaType&& ExecuteLambda); :增加有参数的LambdaPass。
|
||||
- FRDGPassRef AddPass(FRDGEventName&& Name, const FShaderParametersMetadata* ParametersMetadata, const void* ParameterStruct, ERDGPassFlags Flags, ExecuteLambdaType&& ExecuteLambda); :增加带有实时生成结构体的LambdaPass
|
||||
- FRDGPassRef AddPass(FRDGEventName&& Name, ERDGPassFlags Flags, ExecuteLambdaType&& ExecuteLambda);:增加没有参数的LambdaPass
|
||||
- QueueTextureExtraction():在Builder执行末期, 提取池内纹理到指定的指针. 对于RDG创建的资源, 这将延长GPU资源的生命周期,直到执行,指针被填充. 如果指定,纹理将转换为AccessFinal状态, 否则将转换为kDefaultAccessFinal状态。
|
||||
- QueueBufferExtraction():在Builder执行末期, 提取缓冲区到指定的指针。
|
||||
- PreallocateTexture()/PreallocateBuffer():预分配资源. 只对RDG创建的资源, 会强制立即分配底层池内资源, 有效地将其推广到外部资源. 这将增加内存压力,但允许使用GetPooled{Texture, Buffer}查询池中的资源. 主要用于增量地将代码移植到RDG.
|
||||
- GetPooledTexture()/GetPooledBuffer():立即获取底层资源, 只允许用于注册或预分配的资源。
|
||||
- SetTextureAccessFinal()/SetBufferAccessFinal():设置执行之后的状态。
|
||||
- 变量
|
||||
- RDG对象注册表
|
||||
- FRDGPassRegistry Passes;
|
||||
- FRDGTextureRegistry Textures;
|
||||
- FRDGBufferRegistry Buffers;
|
||||
- FRDGViewRegistry Views;
|
||||
- FRDGUniformBufferRegistry UniformBuffers;
|
||||
|
||||
### FRDGBuilder::Compile
|
||||
RDG编译期间的逻辑非常复杂,步骤繁多,先后经历构建生产者和消费者的依赖关系,确定Pass的裁剪等各类标记,调整资源的生命周期,裁剪Pass,处理Pass的资源转换和屏障,处理异步计算Pass的依赖和引用关系,查找并建立分叉和合并Pass节点,合并所有具体相同渲染目标的光栅化Pass等步骤。
|
||||
|
||||
# RDG开发
|
||||
### 注册外部资源
|
||||
如果我们已有非RDG创建的资源,可以在RDG使用么?答案是可以,通过FRDGBuilder::RegisterExternalXXX接口可以完成将外部资源注册到RDG系统中。下面以注册纹理为例:
|
||||
```c++
|
||||
// 在RDG外创建RHI资源.
|
||||
FRHIResourceCreateInfo CreateInfo;
|
||||
FTexture2DRHIRef MyRHITexture = RHICreateTexture2D(1024, 768, PF_B8G8R8A8, 1, 1, TexCreate_CPUReadback, CreateInfo);
|
||||
|
||||
// 将外部创建的RHI资源注册成RDG资源.
|
||||
FRDGTextureRef MyExternalRDGTexture = GraphBuilder.RegisterExternalTexture(MyRHITexture);
|
||||
```
|
||||
需要注意的是,外部注册的资源,RDG无法控制和管理其生命周期,需要保证RDG使用期间外部资源的生命周期处于正常状态,否则将引发异常甚至程序崩溃。
|
||||
|
||||
如果想从RDG资源获取RHI资源的实例,以下代码可达成:
|
||||
```c++
|
||||
FRHITexture* MyRHITexture = MyRDGTexture.GetRHI();
|
||||
```
|
||||
|
||||
用图例展示RHI资源和RDG资源之间的转换关系:
|
||||
- FRHIResource =>FRDGBuilder::RegisterExternalXXX =>FRDGResource
|
||||
- FRDGResource => FRDGResource::GetRHI => FRHIResource
|
||||
|
||||
### 提取资源
|
||||
RDG收集Pass之后并非立即执行,而是延迟执行(包括资源被延迟创建或分配),这就导致了一个问题:如果想将渲染后的资源赋值给某个变量,无法使用立即模式,需要适配延迟执行模式。这种适配延迟执行的资源提取是通过以下接口来实现的:
|
||||
- FRDGBuilder::QueueTextureExtraction
|
||||
- FRDGBuilder::QueueBufferExtraction
|
||||
|
||||
```c++
|
||||
// 创建RDG纹理.
|
||||
FRDGTextureRef MyRDGTexture;
|
||||
|
||||
FRDGTextureDesc MyTextureDesc = FRDGTextureDesc::Create2D(OutputExtent, HistoryPixelFormat, FClearValueBinding::Black, TexCreate_ShaderResource | TexCreate_UAV);
|
||||
|
||||
MyRDGTexture = GraphBuilder.CreateTexture(MyTextureDesc, "MyRDGTexture", ERDGTextureFlags::MultiFrame);
|
||||
|
||||
// 创建UAV并作为Pass的shader参数.
|
||||
(......)
|
||||
PassParameters->MyRDGTextureUAV = GraphBuilder.CreateUAV(MyRDGTexture);
|
||||
(......)
|
||||
|
||||
// 增加Pass, 以便渲染图像到MyRDGTextureUAV.
|
||||
FComputeShaderUtils::AddPass(GraphBuilder, RDG_EVENT_NAME("MyCustomPass", ...), ComputeShader, PassParameters, FComputeShaderUtils::GetGroupCount(8, 8));
|
||||
|
||||
// 入队提取资源.
|
||||
TRefCountPtr<IPooledRenderTarget>* OutputRT;
|
||||
GraphBuilder.QueueTextureExtraction(MyRDGTexture, &OutputRT);
|
||||
|
||||
// 对提取的OutputRT进行后续操作.
|
||||
(......)
|
||||
```
|
||||
|
||||
# RDG调试
|
||||
RDG系统存在一些控制台命令,其名称和描述如下:
|
||||
|控制台变量|描述|
|
||||
|---|---|
|
||||
|**r.RDG.AsyncCompute**|控制异步计算策略:0-禁用;1-为异步计算Pass启用标记(默认);2-开启所有使用compute命令列表的计算通道。|
|
||||
|**r.RDG.Breakpoint**|当满足某些条件时,断点到调试器的断点位置。0-禁用,1~4-不同的特殊调试模式。|
|
||||
|**r.RDG.ClobberResources**|在分配时间用指定的清理颜色清除所有渲染目标和纹理/缓冲UAV。用于调试。|
|
||||
|**r.RDG.CullPasses**|RDG是否开启裁剪无用的Pass。0-禁用,1-开启(默认)。|
|
||||
|**r.RDG.Debug**|允许输出在连接和执行过程中发现的效率低下的警告。|
|
||||
|**r.RDG.Debug.FlushGPU**|开启每次Pass执行后刷新指令到GPU。当设置(r.RDG.AsyncCompute=0)时禁用异步计算。|
|
||||
|**r.RDG.Debug.GraphFilter**|将某些调试事件过滤到特定的图中。|
|
||||
|**r.RDG.Debug.PassFilter**|将某些调试事件过滤到特定的Pass。|
|
||||
|**r.RDG.Debug.ResourceFilter**|将某些调试事件过滤到特定的资源。|
|
||||
|**r.RDG.DumpGraph**|将多个可视化日志转储到磁盘。0-禁用,1-显示生产者、消费者Pass依赖,2-显示资源状态和转换,3-显示图形、异步计算的重叠。|
|
||||
|**r.RDG.ExtendResourceLifetimes**|RDG将把资源生命周期扩展到图的全部长度。会增加内存的占用。|
|
||||
|**r.RDG.ImmediateMode**|在创建Pass时执行Pass。当在Pass的Lambda中崩溃时,连接代码的调用堆栈非常有用。|
|
||||
|**r.RDG.MergeRenderPasses**|图形将合并相同的、连续的渲染通道到一个单一的渲染通道。0-禁用,1-开启(默认)。|
|
||||
|**r.RDG.OverlapUAVs**|RDG将在需要时重叠UAV的工作。如果禁用,UAV屏障总是插入。|
|
||||
|**r.RDG.TransitionLog**|输出资源转换到控制台。|
|
||||
|**r.RDG.VerboseCSVStats**|控制RDG的CSV分析统计的详细程度。0-为图形执行生成一个CSV配置文件,1-为图形执行的每个阶段生成一个CSV文件。|
|
||||
|
||||
除了以上列出的RDG控制台,还有一些命令可以显示RDG系统运行过程中的有用信息。
|
||||
`vis`列出所有有效的纹理,输入之后可能显示如下所示的信息:
|
||||
@@ -0,0 +1,9 @@
|
||||
---
|
||||
title: 剖析虚幻渲染体系(17)- 实时光线追踪
|
||||
date: 2024-02-05 22:02:57
|
||||
excerpt:
|
||||
tags:
|
||||
rating: ⭐
|
||||
---
|
||||
# 前言
|
||||
原文地址:https://www.cnblogs.com/timlly/p/16687324.html
|
||||
Reference in New Issue
Block a user