25 KiB
title, date, excerpt, tags, rating
| title | date | excerpt | tags | rating |
|---|---|---|---|---|
| 剖析虚幻渲染体系(04)- 延迟渲染管线 | 2024-02-07 22:29:32 | ⭐ |
前言
https://www.cnblogs.com/timlly/p/14732412.html
延迟渲染管线
由于最耗时的光照计算延迟到后处理阶段,所以跟场景的物体数量解耦,只跟Render Targe尺寸相关,复杂度是O(Nlight×WRT×HRT)。所以,延迟渲染在应对复杂的场景和光源数量的场景比较得心应手,往往能得到非常好的性能提升。 但是,也存在一些缺点,如需多一个通道来绘制几何信息,需要多渲染纹理(MRT)的支持,更多的CPU和GPU显存占用,更高的带宽要求,有限的材质呈现类型,难以使用MSAA等硬件抗锯齿,存在画面较糊的情况等等。此外,应对简单场景时,可能反而得不到渲染性能方面的提升。延迟渲染可以针对不同的平台和API使用不同的优化改进技术,从而产生了诸多变种。下面是其中部分变种:
Deferred Lighting(Light Pre-Pass)
又被称为Light Pre-Pass,它和Deferred Shading的不同在于需要三个Pass:
- 第一个Pass叫Geometry Pass:只输出每个像素光照计算所需的几何属性(法线、深度)到GBuffer中。
- 第二个Pass叫Lighting Pass:存储光源属性(如Normal * LightDir、LightColor、Specular)到LBuffer(Light Buffer,光源缓冲区)。
- 第三个Pass叫Secondary Geometry Pass:获取GBuffer和LBuffer的数据,重建每个像素计算光照所需的数据,执行光照计算。
与Deferred Shading相比,Deferred lighting的优势在于G-Buffer所需的尺寸急剧减少,允许更多的材质类型呈现,较好第支持MSAA等。劣势是需要绘制场景两次,增加了Draw Call。 另外,Deferred lighting还有个优化版本,做法与上面所述略有不同,具体参见文献Light Pre-Pass。
Tiled-Based Deferred Rendering(TBDR)
Tiled-Based Deferred Rendering译名是基于瓦片的渲染,简称TBDR,它的核心思想在于将渲染纹理分成规则的一个个四边形(称为Tile),然后利用四边形的包围盒剔除该Tile内无用的光源,只保留有作用的光源列表,从而减少了实际光照计算中的无效光源的计算量。
!
- 将渲染纹理分成一个个均等面积的小块(Tile)。参见上图(b)。
Tile没有统一的固定大小,在不同的平台架构和渲染器中有所不同,不过一般是2的N次方,且长宽不一定相等,可以是16x16、32x32、64x64等等,不宜太小或太大,否则优化效果不明显。PowerVR GPU通常取32x32,而ARM Mali GPU取16x16。 !

-
根据Tile内的Depth范围计算出其Bounding Box。 !
 TBDR中的每个Tile内的深度范围可能不一样,由此可得到不同大小的Bounding Box。
TBDR中的每个Tile内的深度范围可能不一样,由此可得到不同大小的Bounding Box。 -
根据Tile的Bounding Box和Light的Bounding Box,执行求交。
除了无衰减的方向光,其它类型的光源都可以根据位置和衰减计算得到其Bounding Box。
- 摒弃不相交的Light,得到对Tile有作用的Light列表。参见上图(c)。
- 遍历所有Tile,获取每个Tile的有作业的光源索引列表,计算该Tile内所有像素的光照结果。
由于TBDR可以摒弃很多无作用的光源,能够避免很多无效的光照计算,目前已被广泛采用与移动端GPU架构中,形成了基于硬件加速的TBDR:! PowerVR的TBDR架构,和立即模式的架构相比,在裁剪之后光栅化之前增加了Tiling阶段,增加了On-Chip Depth Buffer和Color Buffer,以更快地存取深度和颜色。
PowerVR的TBDR架构,和立即模式的架构相比,在裁剪之后光栅化之前增加了Tiling阶段,增加了On-Chip Depth Buffer和Color Buffer,以更快地存取深度和颜色。
下图是PowerVR Rogue家族的Series7XT系列GPU和的硬件架构示意图:
!
Clustered Deferred Rendering
Clustered Deferred Rendering是分簇延迟渲染,与TBDR的不同在于对深度进行了更细粒度的划分,从而避免TBDR在深度范围跳变很大(中间无任何有效像素)时产生的光源裁剪效率降低的问题。
! Clustered Deferred Rendering的核心思想是将深度按某种方式细分为若干份,从而更加精确地计算每个簇的包围盒,进而更精准地裁剪光源,避免深度不连续时的光源裁剪效率降低。
Clustered Deferred Rendering的核心思想是将深度按某种方式细分为若干份,从而更加精确地计算每个簇的包围盒,进而更精准地裁剪光源,避免深度不连续时的光源裁剪效率降低。
上图的分簇方法被称为隐式(Implicit)分簇法,实际上存在显式(Explicit)分簇法,可以进一步精确深度细分,以实际的深度范围计算每个族的包围盒:! 显式(Explicit)的深度分簇更加精确地定位到每簇的包围盒。
显式(Explicit)的深度分簇更加精确地定位到每簇的包围盒。
下图是Tiled、Implicit、Explicit深度划分法的对比图:!
VisibilityBuffer
Visibility Buffer与Deferred Texturing非常类似,是Deferred Lighting更加大胆的改进方案,核心思路是:为了减少GBuffer占用(GBuffer占用大意味着带宽大能耗大),不渲染GBuffer,改成渲染Visibility Buffer。Visibility Buffer上只存三角形和实例id,有了这些属性,在计算光照阶段(shading)分别从UAV和bindless texture里面读取真正需要的vertex attributes和贴图的属性,根据uv的差分自行计算mip-map(下图)。! GBuffer和Visibility Buffer渲染管线对比示意图。后者在由Visiblity阶段取代前者的Gemotry Pass,此阶段只记录三角形和实例id,可将它们压缩进4bytes的Buffer中,从而极大地减少了显存的占用。
GBuffer和Visibility Buffer渲染管线对比示意图。后者在由Visiblity阶段取代前者的Gemotry Pass,此阶段只记录三角形和实例id,可将它们压缩进4bytes的Buffer中,从而极大地减少了显存的占用。
此方法虽然可以减少对Buffer的占用,但需要bindless texture的支持,对GPU Cache并不友好(相邻像素的三角形和实例id跳变大,降低Cache的空间局部性)
Deferred Adaptive Compute Shading
Deferred Adaptive Compute Shading的核心思想在于将屏幕像素按照某种方式划分为5个Level的不同粒度的像素块,以便决定是直接从相邻Level插值还是重新着色。! 此法在渲染UE4的不同场景时,在均方误差(RMSE)、峰值信噪比(PSNR)、平均结构相似性(MSSIM)都能获得良好的指标。(下图)!
此法在渲染UE4的不同场景时,在均方误差(RMSE)、峰值信噪比(PSNR)、平均结构相似性(MSSIM)都能获得良好的指标。(下图)! 渲染同一场景和画面时,对比Checkerboard(棋盘)着色方法,相同时间内,DACS的均方误差(RMSE)只是前者的21.5%,相同图像质量(MSSIM)下,DACS的时间快了4.22倍。
渲染同一场景和画面时,对比Checkerboard(棋盘)着色方法,相同时间内,DACS的均方误差(RMSE)只是前者的21.5%,相同图像质量(MSSIM)下,DACS的时间快了4.22倍。
ForwardRendering
Forward+ Rendering
Forward+ 也被称为Tiled Forward Rendering,为了提升前向渲染光源的数量,它增加了光源剔除阶段,有3个Pass:depth prepass,light culling pass,shading pass。
light culling pass和瓦片的延迟渲染类似,将屏幕划分成若干个Tile,将每个Tile和光源求交,有效的光源写入到Tile的光源列表,以减少shading阶段的光源数量。! +存在由于街头锥体拉长后在几何边界产生误报(False positives,可以通过separating axis theorem (SAT)改善)的情况。
+存在由于街头锥体拉长后在几何边界产生误报(False positives,可以通过separating axis theorem (SAT)改善)的情况。
-
Cluster Forward Rendering Cluster Forward Rendering和Cluster Deferred Rendering类似,将屏幕空间划分成均等Tile,深度细分成一个个簇,进而更加细粒度地裁剪光源。算法类似,这里就不累述了。
-
Volume Tiled Forward Rendering Volume Tiled Forward Rendering在Tiled和Clusterer的前向渲染基础上扩展的一种技术,旨在提升场景的光源支持数量,论文作者认为可以达到400万个光源的场景以30FPS实时渲染。它由以下步骤组成:
1.1 计算Grid(Volume Tile)的尺寸。给定Tile尺寸(tx,ty)(<28><>,<2C><>)和屏幕分辨率(w,h)(<28>,ℎ),可以算出屏幕的细分数量(Sx,Sy)(<28><>,<2C><>):
(Sx,Sy)=(∣∣∣wtx∣∣∣, ∣∣∣hty∣∣∣)(<28><>,<2C><>)=(|<7C><><EFBFBD>|, |ℎ<><E2848E>|)
深度方向的细分数量为:
SZ=∣∣∣log(Zfar/Znear)log(1+2tanθSy)∣∣∣<E288A3><E288A3>=|log(<28><><EFBFBD><EFBFBD>/<2F><><EFBFBD><EFBFBD><EFBFBD>)log(1+2tan<6E><E281A1><EFBFBD>)|
1.2 计算每个Volume Tile的AABB。结合下图,每个Tile的AABB边界计算如下:

knear=Znear(1+2tan(θ)Sy)kkfar=Znear(1+2tan(θ)Sy)k+1pmin=(Sx⋅i, Sy⋅j)pmax=(Sx⋅(i+1), Sy⋅(j+1))<29><><EFBFBD><EFBFBD><EFBFBD>=<3D><><EFBFBD><EFBFBD><EFBFBD>(1+2tan(<28>)<29><>)<29><><EFBFBD><EFBFBD><EFBFBD>=<3D><><EFBFBD><EFBFBD><EFBFBD>(1+2tan(<28>)<29><>)<29>+1<><31><EFBFBD><EFBFBD>=(<28><>⋅<EFBFBD>, <><C2A0>⋅<EFBFBD>)<29><><EFBFBD><EFBFBD>=(<28><>⋅(<28>+1), <><C2A0>⋅(<28>+1))
2、更新阶段:
2.1 深度Pre-pass。只记录非半透明物体的深度。
2.2 标记激活的Tile。
2.3 创建和压缩Tile列表。
2.4 将光源赋给Tile。每个线程组执行一个激活的Volume Tile,利用Tile的AABB和场景中所有的光源求交(可用BVH减少求交次数),将相交的光源索引记录到对应Tile的光源列表(每个Tile的光源数据是光源列表的起始位置和光源的数量):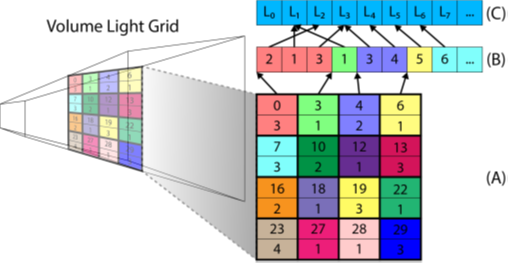 2.5 着色。此阶段与前述方法无特别差异。
2.5 着色。此阶段与前述方法无特别差异。
基于体素分块的渲染虽然能够满足海量光源的渲染,但也存在Draw Call数量攀升和自相似体素瓦片(Self-Similar Volume Tiles,离摄像机近的体素很小而远的又相当大)的问题。
UE渲染相关
FSceneRenderer
FSceneRenderer是UE场景渲染器父类,是UE渲染体系的大脑和发动机,在整个渲染体系拥有举足轻重的位置,主要用于处理和渲染场景,生成RHI层的渲染指令。
// Engine\Source\Runtime\Renderer\Private\SceneRendering.h
// 场景渲染器
class FSceneRenderer
{
public:
FScene* Scene; // 被渲染的场景
FSceneViewFamily ViewFamily; // 被渲染的场景视图族(保存了需要渲染的所有view)。
TArray<FViewInfo> Views; // 需要被渲染的view实例。
FMeshElementCollector MeshCollector; // 网格收集器
FMeshElementCollector RayTracingCollector; // 光追网格收集器
// 可见光源信息
TArray<FVisibleLightInfo,SceneRenderingAllocator> VisibleLightInfos;
// 阴影相关的数据
TArray<FParallelMeshDrawCommandPass*, SceneRenderingAllocator> DispatchedShadowDepthPasses;
FSortedShadowMaps SortedShadowsForShadowDepthPass;
// 特殊标记
bool bHasRequestedToggleFreeze;
bool bUsedPrecomputedVisibility;
// 使用全场景阴影的点光源列表(可通过r.SupportPointLightWholeSceneShadows开关)
TArray<FName, SceneRenderingAllocator> UsedWholeScenePointLightNames;
// 平台Level信息
ERHIFeatureLevel::Type FeatureLevel;
EShaderPlatform ShaderPlatform;
(......)
public:
FSceneRenderer(const FSceneViewFamily* InViewFamily,FHitProxyConsumer* HitProxyConsumer);
virtual ~FSceneRenderer();
// FSceneRenderer接口(注意部分是空实现体和抽象接口)
// 渲染入口
virtual void Render(FRHICommandListImmediate& RHICmdList) = 0;
virtual void RenderHitProxies(FRHICommandListImmediate& RHICmdList) {}
// 场景渲染器实例
static FSceneRenderer* CreateSceneRenderer(const FSceneViewFamily* InViewFamily, FHitProxyConsumer* HitProxyConsumer);
void PrepareViewRectsForRendering();
#if WITH_MGPU // 多GPU支持
void ComputeViewGPUMasks(FRHIGPUMask RenderTargetGPUMask);
#endif
// 更新每个view所在的渲染纹理的结果
void DoCrossGPUTransfers(FRHICommandListImmediate& RHICmdList, FRHIGPUMask RenderTargetGPUMask);
// 遮挡查询接口和数据
bool DoOcclusionQueries(ERHIFeatureLevel::Type InFeatureLevel) const;
void BeginOcclusionTests(FRHICommandListImmediate& RHICmdList, bool bRenderQueries);
static FGraphEventRef OcclusionSubmittedFence[FOcclusionQueryHelpers::MaxBufferedOcclusionFrames];
void FenceOcclusionTests(FRHICommandListImmediate& RHICmdList);
void WaitOcclusionTests(FRHICommandListImmediate& RHICmdList);
bool ShouldDumpMeshDrawCommandInstancingStats() const { return bDumpMeshDrawCommandInstancingStats; }
static FGlobalBoundShaderState OcclusionTestBoundShaderState;
static bool ShouldCompositeEditorPrimitives(const FViewInfo& View);
// 等待场景渲染器执行完成和清理工作以及最终删除
static void WaitForTasksClearSnapshotsAndDeleteSceneRenderer(FRHICommandListImmediate& RHICmdList, FSceneRenderer* SceneRenderer, bool bWaitForTasks = true);
static void DelayWaitForTasksClearSnapshotsAndDeleteSceneRenderer(FRHICommandListImmediate& RHICmdList, FSceneRenderer* SceneRenderer);
// 其它接口
static FIntPoint ApplyResolutionFraction(...);
static FIntPoint QuantizeViewRectMin(const FIntPoint& ViewRectMin);
static FIntPoint GetDesiredInternalBufferSize(const FSceneViewFamily& ViewFamily);
static ISceneViewFamilyScreenPercentage* ForkScreenPercentageInterface(...);
static int32 GetRefractionQuality(const FSceneViewFamily& ViewFamily);
protected:
(......)
#if WITH_MGPU // 多GPU支持
FRHIGPUMask AllViewsGPUMask;
FRHIGPUMask GetGPUMaskForShadow(FProjectedShadowInfo* ProjectedShadowInfo) const;
#endif
// ----可在所有渲染器共享的接口----
// --渲染流程和MeshPass相关接口--
void OnStartRender(FRHICommandListImmediate& RHICmdList);
void RenderFinish(FRHICommandListImmediate& RHICmdList);
void SetupMeshPass(FViewInfo& View, FExclusiveDepthStencil::Type BasePassDepthStencilAccess, FViewCommands& ViewCommands);
void GatherDynamicMeshElements(...);
void RenderDistortion(FRHICommandListImmediate& RHICmdList);
void InitFogConstants();
bool ShouldRenderTranslucency(ETranslucencyPass::Type TranslucencyPass) const;
void RenderCustomDepthPassAtLocation(FRHICommandListImmediate& RHICmdList, int32 Location);
void RenderCustomDepthPass(FRHICommandListImmediate& RHICmdList);
void RenderPlanarReflection(class FPlanarReflectionSceneProxy* ReflectionSceneProxy);
void InitSkyAtmosphereForViews(FRHICommandListImmediate& RHICmdList);
void RenderSkyAtmosphereLookUpTables(FRHICommandListImmediate& RHICmdList);
void RenderSkyAtmosphere(FRHICommandListImmediate& RHICmdList);
void RenderSkyAtmosphereEditorNotifications(FRHICommandListImmediate& RHICmdList);
// ---阴影相关接口---
void InitDynamicShadows(FRHICommandListImmediate& RHICmdList, FGlobalDynamicIndexBuffer& DynamicIndexBuffer, FGlobalDynamicVertexBuffer& DynamicVertexBuffer, FGlobalDynamicReadBuffer& DynamicReadBuffer);
bool RenderShadowProjections(FRHICommandListImmediate& RHICmdList, const FLightSceneInfo* LightSceneInfo, IPooledRenderTarget* ScreenShadowMaskTexture, IPooledRenderTarget* ScreenShadowMaskSubPixelTexture, bool bProjectingForForwardShading, bool bMobileModulatedProjections, const struct FHairStrandsVisibilityViews* InHairVisibilityViews);
TRefCountPtr<FProjectedShadowInfo> GetCachedPreshadow(...);
void CreatePerObjectProjectedShadow(...);
void SetupInteractionShadows(...);
void AddViewDependentWholeSceneShadowsForView(...);
void AllocateShadowDepthTargets(FRHICommandListImmediate& RHICmdList);
void AllocatePerObjectShadowDepthTargets(FRHICommandListImmediate& RHICmdList, ...);
void AllocateCachedSpotlightShadowDepthTargets(FRHICommandListImmediate& RHICmdList, ...);
void AllocateCSMDepthTargets(FRHICommandListImmediate& RHICmdList, ...);
void AllocateRSMDepthTargets(FRHICommandListImmediate& RHICmdList, ...);
void AllocateOnePassPointLightDepthTargets(FRHICommandListImmediate& RHICmdList, ...);
void AllocateTranslucentShadowDepthTargets(FRHICommandListImmediate& RHICmdList, ...);
bool CheckForProjectedShadows(const FLightSceneInfo* LightSceneInfo) const;
void GatherShadowPrimitives(...);
void RenderShadowDepthMaps(FRHICommandListImmediate& RHICmdList);
void RenderShadowDepthMapAtlases(FRHICommandListImmediate& RHICmdList);
void CreateWholeSceneProjectedShadow(FLightSceneInfo* LightSceneInfo, ...);
void UpdatePreshadowCache(FSceneRenderTargets& SceneContext);
void InitProjectedShadowVisibility(FRHICommandListImmediate& RHICmdList);
void GatherShadowDynamicMeshElements(FGlobalDynamicIndexBuffer& DynamicIndexBuffer, FGlobalDynamicVertexBuffer& DynamicVertexBuffer, FGlobalDynamicReadBuffer& DynamicReadBuffer);
// --光源接口--
static void GetLightNameForDrawEvent(const FLightSceneProxy* LightProxy, FString& LightNameWithLevel);
static void GatherSimpleLights(const FSceneViewFamily& ViewFamily, ...);
static void SplitSimpleLightsByView(const FSceneViewFamily& ViewFamily, ...);
// --可见性接口--
void PreVisibilityFrameSetup(FRHICommandListImmediate& RHICmdList);
void ComputeViewVisibility(FRHICommandListImmediate& RHICmdList, ...);
void PostVisibilityFrameSetup(FILCUpdatePrimTaskData& OutILCTaskData);
// --其它接口--
void GammaCorrectToViewportRenderTarget(FRHICommandList& RHICmdList, const FViewInfo* View, float OverrideGamma);
FRHITexture* GetMultiViewSceneColor(const FSceneRenderTargets& SceneContext) const;
void UpdatePrimitiveIndirectLightingCacheBuffers();
bool ShouldRenderSkyAtmosphereEditorNotifications();
void ResolveSceneColor(FRHICommandList& RHICmdList);
(......)
};
FSceneRenderer由游戏线程的FRendererModule::BeginRenderingViewFamily负责创建和初始化,然后传递给渲染线程。渲染线程会调用FSceneRenderer::Render(),渲染完返回后,会删除FSceneRenderer的实例。也就是说,FSceneRenderer会被每帧创建和销毁。
FSceneRenderer拥有两个子类:FMobileSceneRenderer和FDeferredShadingSceneRenderer。
FMobileSceneRenderer是用于移动平台的场景渲染器,默认采用了前向渲染的流程。
FDeferredShadingSceneRenderer虽然名字叫做延迟着色场景渲染器,但其实集成了包含前向渲染和延迟渲染的两种渲染路径,是PC和主机平台的默认场景渲染器(笔者刚接触伊始也被这蜜汁取名迷惑过)。
FDeferredShadingSceneRenderer
FDeferredShadingSceneRenderer主要包含了MeshPass、光源、阴影、光线追踪、反射、可见性等几大类接口。其中最重要的接口非FDeferredShadingSceneRenderer::Render()莫属,它是FDeferredShadingSceneRenderer的渲染主入口,主流程和重要接口的调用都直接或间接发生它内部。
则可以划分成以下主要阶段:
- FScene::UpdateAllPrimitiveSceneInfos:更新所有图元的信息到GPU,若启用了GPUScene,将会用二维纹理或StructureBuffer来存储图元的信息。
- FSceneRenderTargets::Allocate:若有需要(分辨率改变、API触发),重新分配场景的渲染纹理,以保证足够大的尺寸渲染对应的view。
- InitViews:采用裁剪若干方式初始化图元的可见性,设置可见的动态阴影,有必要时会对阴影平截头体和世界求交(全场阴影和逐物体阴影)。
- PrePass / Depth only pass:提前深度Pass,用来渲染不透明物体的深度。此Pass只会写入深度而不会写入颜色,写入深度时有disabled、occlusion only、complete depths三种模式,视不同的平台和Feature Level决定。通常用来建立Hierarchical-Z,以便能够开启硬件的Early-Z技术,提升Base Pass的渲染效率。
- Base pass:也就是前面章节所说的几何通道。 用来渲染不透明物体(Opaque和Masked材质)的几何信息,包含法线、深度、颜色、AO、粗糙度、金属度等等。这些几何信息会写入若干张GBuffer中。此阶段不会计算动态光源的贡献,但会计算Lightmap和天空光的贡献。
- Issue Occlusion Queries / BeginOcclusionTests:开启遮挡渲染,此帧的渲染遮挡数据用于下一帧
InitViews阶段的遮挡剔除。此阶段主要使用物体的包围盒来渲染,也可能会打包相近物体的包围盒以减少Draw Call。 - Lighting:此阶段也就是前面章节所说的光照通道,是标准延迟着色和分块延迟着色的混合体。会计算开启阴影的光源的阴影图,也会计算每个灯光对屏幕空间像素的贡献量,并累计到Scene Color中。此外,还会计算光源也对translucency lighting volumes的贡献量。
- Fog在屏幕空间计算雾和大气对不透明物体表面像素的影响。
- Translucency:渲染半透明物体阶段。所有半透明物体由远到近(视图空间)逐个绘制到离屏渲染纹理(offscreen render target,代码中叫separate translucent render target)中,接着用单独的pass以正确计算和混合光照结果。
- Post Processing:后处理阶段。包含了不需要GBuffer的Bloom、色调映射、Gamma校正等以及需要GBuffer的SSR、SSAO、SSGI等。此阶段会将半透明的渲染纹理混合到最终的场景颜色中。
FScene::UpdateAllPrimitiveSceneInfos
FScene::UpdateAllPrimitiveSceneInfos的调用发生在FDeferredShadingSceneRenderer::Render的第一行:
// Engine\Source\Runtime\Renderer\Private\DeferredShadingRenderer.cpp
void FDeferredShadingSceneRenderer::Render(FRHICommandListImmediate& RHICmdList)
{
Scene->UpdateAllPrimitiveSceneInfos(RHICmdList, true);
(......)
}
FScene::UpdateAllPrimitiveSceneInfos的主要作用是删除、增加、更新CPU侧的图元数据,且同步到GPU端。其中GPU的图元数据存在两种方式:
- 每个图元独有一个Uniform Buffer。在shader中需要访问图元的数据时从该图元的Uniform Buffer中获取即可。这种结构简单易理解,兼容所有FeatureLevel的设备。但是会增加CPU和GPU的IO,降低GPU的Cache命中率。
- 使用Texture2D或StructuredBuffer的GPU Scene,所有图元的数据按规律放置到此。在shader中需要访问图元的数据时需要从GPU Scene中对应的位置读取数据。需要SM5支持,实现难度高,不易理解,但可减少CPU和GPU的IO,提升GPU Cache命中率,可更好地支持光线追踪和GPU Driven Pipeline。 虽然以上访问的方式不一样,但shader中已经做了封装,使用者不需要区分是哪种形式的Buffer,只需使用以下方式:
// Engine\Shaders\Private\SceneData.ush
struct FPrimitiveSceneData
{
float4x4 LocalToWorld;
float4 InvNonUniformScaleAndDeterminantSign;
float4 ObjectWorldPositionAndRadius;
float4x4 WorldToLocal;
float4x4 PreviousLocalToWorld;
float4x4 PreviousWorldToLocal;
float3 ActorWorldPosition;
float UseSingleSampleShadowFromStationaryLights;
float3 ObjectBounds;
float LpvBiasMultiplier;
float DecalReceiverMask;
float PerObjectGBufferData;
float UseVolumetricLightmapShadowFromStationaryLights;
float DrawsVelocity;
float4 ObjectOrientation;
float4 NonUniformScale;
float3 LocalObjectBoundsMin;
uint LightingChannelMask;
float3 LocalObjectBoundsMax;
uint LightmapDataIndex;
float3 PreSkinnedLocalBoundsMin;
int SingleCaptureIndex;
float3 PreSkinnedLocalBoundsMax;
uint OutputVelocity;
float4 CustomPrimitiveData[NUM_CUSTOM_PRIMITIVE_DATA];
};
由此可见,每个图元可访问的数据还是很多的,占用的显存也相当可观,每个图元大约占用576字节,如果场景存在10000个图元(游戏场景很常见),则忽略Padding情况下,这些图元数据总量达到约5.5M。
言归正传,回到C++层看看GPU Scene的定义:
// Engine\Source\Runtime\Renderer\Private\ScenePrivate.h
class FGPUScene
{
public:
// 是否更新全部图元数据,通常用于调试,运行期会导致性能下降。
bool bUpdateAllPrimitives;
// 需要更新数据的图元索引.
TArray<int32> PrimitivesToUpdate;
// 所有图元的bit,当对应索引的bit为1时表示需要更新(同时在PrimitivesToUpdate中).
TBitArray<> PrimitivesMarkedToUpdate;
// 存放图元的GPU数据结构, 可以是TextureBuffer或Texture2D, 但只有其中一种会被创建和生效, 移动端可由Mobile.UseGPUSceneTexture控制台变量设定.
FRWBufferStructured PrimitiveBuffer;
FTextureRWBuffer2D PrimitiveTexture;
// 上传的buffer
FScatterUploadBuffer PrimitiveUploadBuffer;
FScatterUploadBuffer PrimitiveUploadViewBuffer;
// 光照图
FGrowOnlySpanAllocator LightmapDataAllocator;
FRWBufferStructured LightmapDataBuffer;
FScatterUploadBuffer LightmapUploadBuffer;
};
代码略……
总结起来,FScene::UpdateAllPrimitiveSceneInfos的作用是删除、增加图元,以及更新图元的所有数据,包含变换矩阵、自定义数据、距离场数据等。
GPUScene的PrimitivesToUpdate和PrimitivesMarkedToUpdate收集好需要更新的所有图元索引后,会在FDeferredShadingSceneRenderer::Render的InitViews之后同步给GPU:
void FDeferredShadingSceneRenderer::Render(FRHICommandListImmediate& RHICmdList)
{
// 更新GPUScene的数据
Scene->UpdateAllPrimitiveSceneInfos(RHICmdList, true);
(......)
// 初始化View的数据
bDoInitViewAftersPrepass = InitViews(RHICmdList, BasePassDepthStencilAccess, ILCTaskData, UpdateViewCustomDataEvents);
(......)
// 同步CPU端的GPUScene到GPU.
UpdateGPUScene(RHICmdList, *Scene);//5.3 => Scene->GPUScene.Update(GraphBuilder, GetSceneUniforms(), *Scene, ExternalAccessQueue);
(......)
}
UpdateGPUScene()代码略……